Toward
Virtually Embodied AI:
Embedding
Novamente
in a
Simulated World
Ben Goertzel &
Cassio Pennachin
1 Introduction
This document discusses the use of the Novamente AI Engine (see www.agiri.org) to control the behavior of agents in a simulated world. It is brief but reflects a great deal of thought and analysis, and many discussions between the authors and others inside and outside the Novamente project.
The final section discusses a particular example simulation world (EDEN = EDucational Environment for Novamente), but this example is introduced mostly for sake of the clarity that comes with concreteness, rather than because it is a particularly fascinating example. Until that section, the discussion is not focused on any particular simulated world, but is intended to be totally general in nature. Further documentation, more specific in nature, will be required for any particular Novamente/simulation-world project (including any pragmatic implementation of EDEN).
This is not a highly technical document, but merely an abstract “conceptual design” document, which will in time be supplemented with documents specifying detailed technical designs. In spite of the abstract level of discussion, however, this is an internal document for Novamente-savvy readers, rather than a general document for outsiders. Knowledge at the level of the Novamente overview papers on the agiri.org website will be required to get anything at all out of the document.
1.1 What Do We Mean by a Simulation World?
For the purposes of this document, it is assumed that the simulation world consists of a simulated 2D or (the main case of interest) 3D physical environment, and that Novamente is given control of one or more agents, each one of which is localized in a particular “body” within the environment. Each body is supplied with sensors and actuators, and
- Each sensor results in a stream of perceptual relationships being presented to Novamente, over time. These relationships are primitive perceptual relationship types, for example the output of a camera eye might be represented using a relationship (PixelAt n m c) where n and m are integers representing locations on a camera screen, and c is a list representing a perceived color.
- Each actuator is represented by a function taking one or more arguments, e.g. move(v, a), where s is a float indicating speed and a is a list indicating direction.
The particular set of sensors and actuators involved is very important for practical purposes, although the general approach described in this document works for essentially any set of sensors and actuators. We are thinking in particular of
- Sensors such as: camera eyes, microphones, GPS input, indicators telling the physical location of particular objects, etc.
- Actuators such as: “movement devices” that can move in a specified direction with a specified speed, sensor control devices (e.g. pointing a camera in a certain direction), remote controls (that can direct, say, a remote-control robot in a certain direction)
We are not concerning ourselves here with the details of robot control – for instance, with the mechanisms of controlling a robot arm or steering a robot in a certain direction. This sort of thing can be handled in Novamente, but we feel it’s a less interesting area of focus than higher-level control, and certainly it’s highly context-specific.
Regarding sensory processing, we are willing to make use of existing sense-stream processing tools – for example, if camera-eye input is involved, we are quite willing to use existing vision processing software and feed Novamente its output (the software-architecture required to support this will be discussed below). In this example, we would also like Novamente to have access to the raw output of the camera eye, so that it can carry out subtler perception processing if it judges this appropriate.
Next, we assume that there are particular goals one wants the Novamente-controlled agent to achieve in the simulated environment. These goals may be defined abstractly, but they should be definable formally, in terms of an Evaluator software object that can look at the log of Novamente’s behavior in the simulated world over a period of time and assess the extent to which Novamente has fulfilled its goals. There may be general goals, such as “discover novel information about the world”, and also specific task-oriented goals imposed by the human teachers/programmers.
1.2 Experiential Learning and the Need for an Educational Curriculum
Most “AI” programs that control agents in simulation worlds operate using expert rules. The Novamente approach, on the other hand, is based on experiential interactive learning. Initially, Novamente will be either
- Told nothing about how to act in the simulation world
- Given a set of high-level general (crisp, or more generally, probabilistic) constraints on its behavior, but not given specific behavioral rules
It has to figure out how to act in the simulation world, based on feedback. The feedback is provided via Novamente’s in-built goal system, which reinforces behaviors that appear to help the system achieve its goals, and weaken behaviors that appear to act against the system’s goals. Feedback from human teachers may be incorporated into the learning process, to the extent that Novamente is given an initial goal of pleasing its human teachers.
Experiential learning in a simulated environment is not an easy task, and if a Novamente system is simply started up, given simulated sensors and actuators, and asked to achieve a complex goal, it is very likely to flail around uselessly for a long time, possibly forever. Of course, this would not be true if the system were given a huge enough allocation of computational resources, but we are considering the case of plausible resource allocation. This observation leads to the notion of a systematic educational program for Novamente.
While the end goals for Novamente may be extremely sophisticated, we consider it important to define a series of progressively more difficult and complex goals, beginning with very simple ones. The goal series must be defined so that, with each goal Novamente learns to achieve, its “internal ontology” of learned cognitive procedures is appropriately enlarged.
The role of experiential learning in shaping a Novamente’s “mind-space” should not be underestimated. Recall that the Novamente software design does not provide a full “cognitive architecture,” only a high-level cognitive architecture, and then a set of processes within which a more detailed cognitive architecture may emerge through experiential learning. The detailed cognitive architecture then consists of a “dual network” (hierarchy/heterarchy) of learned procedures, appropriate for various sorts of activity in various sorts of context. For the cognitive architecture to build up properly, requires the right sort of experience. The “educational program” described in Section 4 of this document, in the context of EDEN, describes an example of what we think will be the right sort of experience.
1.3 The Value of Simulation Worlds
What is the value of experimenting with Novamente in simulation worlds, as opposed to other things that one might do with Novamente systems?
There are two sorts of answers to this, of course:
- There may be specific practical or scientific reasons why one wants an AI controlling agents in a simulation world, and Novamente may fit the bill
- There may be reasons why controlling agents in a simulation world is a good thing for Novamente AI itself, apart from any external goals
Here we will discuss only the second sort of reason.
The main thing that a simulation world has to offer Novamente development is: integration of perception, action and cognition in the context of goal-achievement. This integration is, we believe, critical to the development of true general intelligence in a Novamente AI system. The reason for this is subtle, and has to do with the psynet model of mind, the theoretical framework underlying the Novamente system. According to the psynet model, the most essential aspects of mind is the network of emergent structures and processes that arises in a complex cognitive system in the course of its self-analysis and its interaction with the world. In order for a sufficiently complex self-organizing internal emergent knowledge/process-network to emerge, goal-directed perception/action/cognition integration seems to be required. Many pragmatically interesting applications of the Novamente codebase – for instance, datamining or text mining applications – do not naturally support this kind of integration, and hence are not as interesting as paths to AGI (in spite of their intense independent interest).
Many people, when they hear about the “simulation world” idea, ask why one wants to mess around with simulations instead of just going the robotics route. We have two main responses to that.
The glib answer is that playing around with robotics/AI combinations inevitably seems to lead to spending 95% of one’s time on robotics and 5% of one’s time on AI. But of course, this glib answer could potentially be circumvented via the addition of a large, dedicated robotics team to the project (not a terribly likely near-term possibility, in fact).
There is a less glib answer as well, which is that getting Novamente to work well in any environment (real or simulated) will initially be a big job – and a job requiring lots of iterated experimentation, with Novamente configurations that vary in various ways. Compared to running experiments in a simulated world is far cheaper, and far more easily parallelizable. Once Novamente has achieved a high level of functionality in a simulated world, exploring its performance in a similar robotically-achieved real-world environment will certainly be an interesting next step.
2 Internal Novamente Structures, Processes and Cognitive Architecture
This section briefly describes the structures
and processes needed to make a Novamente AI Engine function in a simulation
environment.
2.1 Software Architecture Issues
The current Novamente software architecture
is basically adequate for dealing with agent-control in a simulation
world. However, a couple small
additions are required in order to handle this sort of application with
elegance and efficiency. These
additions don’t modify the core AI architecture of the system, they are more at
the software-systems level, pertaining to interactions between core AI
processes and the external world (the simulation world). We will discuss these additions here on a
conceptual level, omitting implementation details.
Firstly, we require a core service, in the
Novamente server, dealing with interactions with the simulation world. A core service is basically a server which
listens to a port for TCP connections and handles them in multiple threads (one
thread would correspond to one interaction channel in this case). This SimulationProxyServer (to invent a plausible
name) will require careful engineering due to the need for real-time
interaction between Novamente and the simulation world.
Next, a special software mechanism may be
desired for perceptual preprocessing, and for action postprocessing. Ideally we would handle all percepts and
actions – no matter how fine-grained -- as schemata inside the Novamente core,
but this strategy would be very demanding on the Novamente system in terms of
processing speed, and would also introduce a lot of complexity into the system,
some of it unnecessary. For initial
experiments, therefore, we feel it probably makes sense to implement the more
elementary processing of perception and action outside the Novamente core. For instance, if dealing with visual
sensors, it may be desirable to use standard, non-Novamente-based algorithms
for elementary vision processing such as edge detection and shape-from-motion
analysis. Similarly, if dealing with
robotic control, it may make sense initially to use standard algorithms to direct
the movements of the joints of a robot arm (having Novamente simply give the
arm its overall desired destination, and any constraints on its motion). Ultimately, a Novamente learning approach
will be useful at these low levels, but for starters we feel it may be better
for Novamente efforts to focus on the cognitive level.
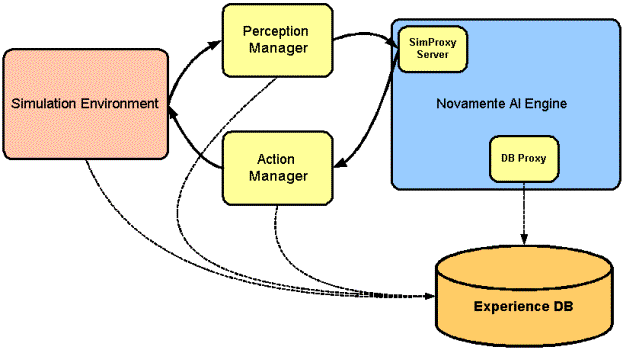
Based on this plan, we posit
PerceptionManager and ActionManager objects, which exist outside the Novamente
core, and relay information between the core and the simulation world. In this approach, the SimulationProxyServer
communicates with these Manager objects rather than with the simulation world
directly.
Finally, it is important that the simulation
world, the Novamente core, and the perception and action Managers all log their
input and outputs into a common database, the ExperienceDB, which can then be
mined later on and studied with both intelligence-improvement and
simulation-world-improvement in mind.
2.2 Cognitive Architecture
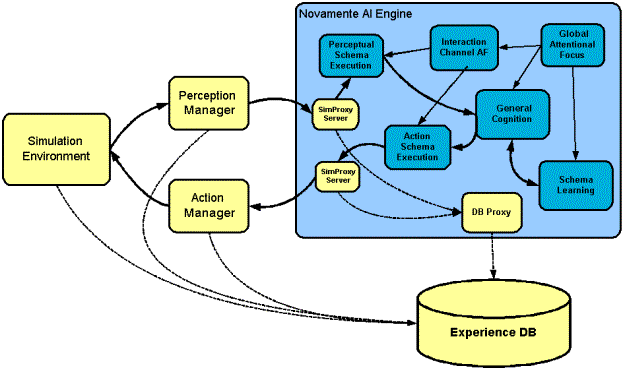
Novamente is quite flexible as regards cognitive architecture, and there are many approaches that can plausibly be taken. The right cognitive architecture for simulated-agent-control will likely only be learned via experience. Here we sketch our initial ideas, which we believe will be serviceable for experimentation.
For the control of a single-interaction-channel agent, we propose a six-Unit Novamente configuration, consisting of Lobes devoted to:
- Perceptual schema execution
- Action schema execution
- General cognition
- Global attentional focus
- Interaction-channel-specific attentional focus
- Schema learning
This is a close-to-maximal architecture: we are not sure we will need this many Lobes, but we are sure we won’t need more than this in the near term.
For early experimentation, the Attentional Focii can be omitted, leaving only 4 lobes.
For initial experimentation, 2 lobes (# 3 and 6) can be used, but this is unlikely to provide adequate performance, because the perception/action schema execution and general cognition are going to be very difficult to schedule together in a single lobe.
Of course, if linguistic communication is part of the simulated world, then a collection of language-processing Lobes must be added, as described in the Novamente book.
2.3 Cognitive Dynamics
Now to the crux of the problem: what MindAgents will be involved here, and for what purposes? How can we relate the MindAgents’ activities to the simulation world itself?
This topic is dealt with in detail in the Experiential Interactive Learning chapter of the Novamente book, and so it will only be briefly reviewed here.
The actions Novamente takes in the simulated world are induced by the invocation of the execute() functions inside SchemaNodes. A very simple action may be induced by a single SchemaNode, but most actions will be carried out via the coordinated activity of multiple SchemaNodes. Thus, from a pragmatic perspective, the essential core of Novamente intelligence in a simulated-world context (and arguably, in any truly AGI-oriented context) is schema learning. Other cognitive processes may be understood from the perspective of how they support schema learning. In this section we will give a quick run-through of key Novamente cognitive processes from a schema-learning-centric perspective, without pretense of completeness.
A comment about the internals of Novamente SchemaNodes is pertinent here. The current version of SchemaNode supports only “first-order” schemata, i.e. its internal schemata do not include either variables or higher-order functions (which may be used to substitute for variables according to mechanisms from combinatory logic). Before simulation-world-oriented schema learning can be seriously undertaken, this deficit must be remedied, and we must implement higher-order SchemaNodes (according to the combinatory-logic approach). A Novamente-focused combinatory logic interpreter has been written by Luke Kaiser, and integration of this with the Novamente core is estimated to be a 1-3 month project for a knowledgeable C++ programmer.
2.3.1 Algorithms for Schema Learning
Schema learning is carried out in Novamente via a combination of probabilistic inference and evolutionary learning, specifically
- Evolutionary learning via
- Genetic programming
- Bayesian Optimization Algorithm (BOA)
- PTL-enhanced BOA
- Probabilistic inference (using the Probabilistic Term Logic (PTL) framework) via:
- Higher-order inference on predicates related to schemata
- Inference on HebbianLinks, providing a form of direct reinforcement learning
2.3.2 Goal Dynamics
Schema learning is driven by goals: the system tries to learn procedures that will help it to fulfill its goals. It tries to learn very specific procedures that will allow it to fulfill its goals in specific contexts, and more abstract procedural patterns that will allow it to fulfill its goals in more broadly defined contexts.
The initial goals of the system are provided by the humans who set the system up (initially, by the programmers; in later Novamente versions perhaps by system administrators through some kind of goal-configuration UI). The mutability or otherwise of these initial goals is, to a large extent, a choice to be made by the same humans who set the goals. Obviously, we humans can overcome and “reprogram” our inborn biological goals, as well as elaborating and refining them; the extent to which AI systems should possess this property is a deep and multifaceted question, which we will not pursue here. The extent to which a Novamente system may be able to effectively mutate or circumvent its initially given goals without actually modifying the given GoalNodes, is also a tricky issue left for analysis elsewhere.
Assuming the initial goals are left immutable, then Novamente is left with cognitive tasks such as:
- Goal refinement: the creation of subgoals for each goal, e.g. if A is a goal it may learn that A = B & C, where B and C are subgoals whose joint achievement is equivalent to achievement of A
- Goal abstraction: It may learn that “D implies A”, where D is a more abstract goal than A
Since a GoalNode is merely a wrapper for a predicate (and hence very similar to a PredicateNode, the difference being how some MindAgents treat it), both of these goal-oriented cognitive tasks may be carried out through generic Novamente probabilistic-inference and PredicateNode-creation methods.
2.3.3 Perception and Action
Perception and action are carried out by schemata, whose inputs may include complex predicates representing patterns observed in the world (the perception case) or patterns in the mind triggering actions (the action case). Most of the learning of perception and action schemata must, we believe, be carried out in the context of a perception-action-cognition loop, rather than in an isolated way. There are many ways to perceive the environment, and a mind needs to find those ways that will allow it to carry out useful actions – for instance, a mind may judge two entities as equal if it has no use to distinguish them. Some of the teaching exercises described below focus on perception or action in isolation, but by and large our inclination is to teach the two things in an integrated way.
2.3.4 Forming and Managing Declarative Knowledge
A large percentage of the Novamente design has to do with the creation and maintenance of declarative knowledge. From a schema-learning-centric perspective, the function of declarative knowledge is to aid with
- The learning of new schemata via inference and BOA (methods that are able to use declarative background knowledge as part of their learning process)
- The refinement of goals via inference and BOA
It is the use of declarative knowledge, via these mechanisms, that allows a Novamente system to learn via experience, rather than approaching each task presented to it by the environment as a brand new optimization problem. Association-formation, probabilistic inference, and various concept and predicate creation heuristics are important here; finding the optimal combination of these processes for a simulation-world context will be a nontrivial task.
2.3.5 Automated Parameter Adaptation
The optimal mixture of cognitive processes for agent-control in simulation-worlds is not known, and may be different in different simulation worlds. Concretely, this means that the importance values associated with MindAgents – and used to allocate time to different MindAgents – will initially be set by heuristic intuition, and then be allowed to adapt over time. Much of this adaptation must be done in the context of simple, early-stage training tasks, because the learning time required for later-stage tasks may be too great to enable extensive experimentation with such parameter settings.
Of course, there are also other parameters besides the MindAgent importance levels to be optimized – internal parameters of various MindAgents. This has implications for the simulation-world test framework, to be discussed below.
3 Test Framework Architecture
The Novamente design tells us how to create a software system capable of adaptively learning to control agents in simulated worlds. However, the design as it now exists doesn’t fill in all the details. There are many free parameters to be tuned, and even beyond that, experience shows us that some of the algorithms and knowledge representation mechanisms will be found to need tweaking as experimentation proceeds. Experimentation is therefore key to this sort of project, and systematic experimentation requires a reliable, properly-designed testing framework.
The most general simulation-world testing framework would have the following properties:
- A batch of tests may be launched from a single machine
- A batch of tests will run on a number of networked machines
- Each batch of tests involves N simulation worlds, potentially running different scenarios
- Each of the simulation worlds involves one or more Novamente systems
- Each scenario comes along with a quantitative fitness function, according to which Novamente performance may be judged
- Each Novamente system controls one or more agents, existing in one or more simulation worlds
- Novamente systems may be created from scratch based on given parameter values, or may be loaded from files (allowing persistence of Novamentes across testing runs)
- Other parameters defining the individual Novamente systems or simulation worlds may be specified
- It is possible to specify which aspects of the Novamente systems should be varied during the experiment
Of course, for pragmatic reasons, it may be worthwhile to create an initial testing framework with less generality. For early experiments, all we really need is a framework so that
- A batch of tests may be launched from a single machine
- A batch of tests will run on a number of networked machines
- Each batch of tests involves N identical simulation worlds, running the same scenario
- The scenario comes along with a quantitative fitness function, according to which Novamente performance may be judged
- Each of the simulation worlds involves a single Novamente system
- Other parameters defining the individual Novamente systems may be specified
- It is possible to specify which aspects of the Novamente systems should be varied during the experiment
The next steps beyond this would be to allow each simulation world to involve a fixed number K of Novamente systems (so that Novamentes can interact with each other), and to allow Novamentes to be loaded from files (allowing knowledge accumulation over time). The test framework may be incrementally expanded so as to gradually work up to full generality.
All test results and configurations must be logged in an ExperimentDB, for subsequent analysis by statistical and machine learning methods.
One point in the above testing-framework description is worthy of further note: In order for testing of various Novamente systems to be carried out in a systematic way, we need to have an automated way of evaluating the success of a given Novamente system in a given scenario. This must be supplied by the humans who have created the scenario, and will ideally be supplied in the form of a quantitative fitness function (i.e. not just a binary indicator of success vs. failure).
Given a fitness function, the testing frameworks described above run tests automatically, using BOA to find the optimal Novamente parameters for the given scenario and fitness function.
We have implemented a Linux-based, BOA-driven distributed testing framework for use in time-series prediction applications, which is currently in heavy use, and which may be modifiable into a simulation-world testing framework with a moderate amount of effort.
4 Stages of Mental Development
The need for a systematic educational program was mentioned above. Of course, one can formulate a specific educational program only in the context of a particular simulation world. However, it is possible to outline an approach to designing educational programs, independently of the details of the simulation world.
Our approach to designing educational programs is based on the notion of stages of mental development. In an abstract sense, this is similar to the educational theories of Jean Piaget, Maria Montessori, and others. However, we will not stick close to the details of any prior stage-oriented educational theory, given our focus on digital rather than human education.
Another influence on our thinking has been the work of Peter Voss and his colleagues on the a2i2 project[1]. Voss’s project involves giving an AI system sensors and actuators, and having it learn to achieve goals in its environment; it also involves a staged educational program. The details of his AI design are quite different from those of Novamente, and as a consequence his specific choice of environment and educational program are not quite perfectly suited for Novamente; but nevertheless, both Novamente and a2i2 could meaningfully be tested in each others’ simulated environments.
We introduce here the notion of a functionality-specific developmental dag.[2] We consider four example functionalities:
- vision
- physical-action-formulation
- goal refinement
- language
- learning by instruction
In each of these cases, one may identify a set of developmental stages so that
- Each stage in the sequence involves the mind learning to create new entities of a certain sort
- The entities the system newly learns to create at stage N, are largely composed as combinations of entities the system knew how to create at stages {1,2,..,N-1}.
An interesting twist is that the “developmental stages” associated with a single functionality are not necessarily arrangeable in a simple linear ordering. Rather, the ordering of developmental stages may take the form of a directed acyclic graph (dag) rather than a simple series of steps. Different developmental subsequences may begin together, as a single sequence, and then branch off, sometimes reconverging. Further, these subsequences will often be interdependent.
Of course, the five examples we will give here don’t tell the whole story. In a separate document, we will present developmental dags corresponding to all aspects of Novamente cognition, and discuss the interdependencies between these sequences. However, elaboration to that extent would not be appropriate in an overview document such as this one.
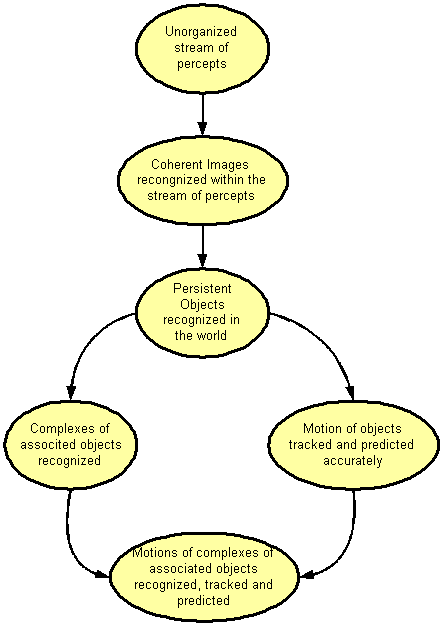
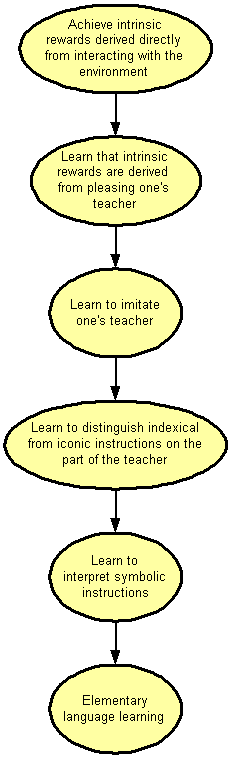
Fig. 1:
Developmental dag for Vision Processing

Fig. 2: Developmental dag for Physical-Action Conception
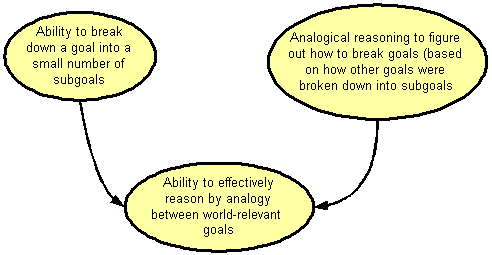
Fig. 3: Developmental dag for Goal Refinement
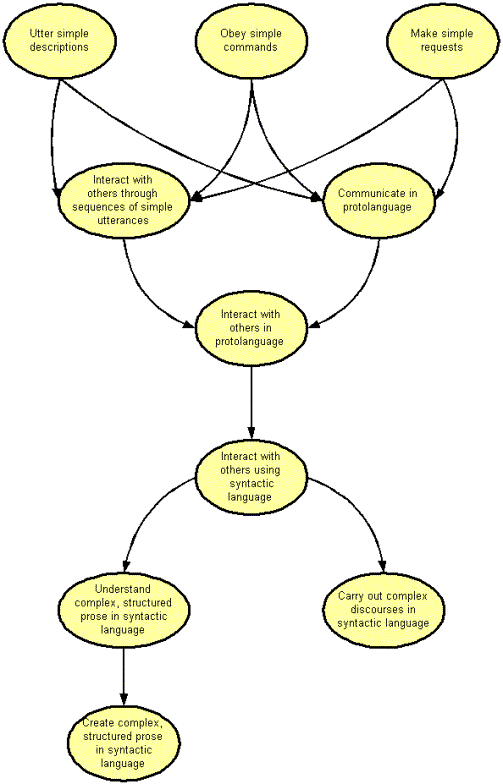
Fig. 4: Developmental dag for Linguistics