Psychometric Description of the True Compatibility Test™ --
A Proprietary Online Matchmaking System
Rense Lange
Illinois State
Board of Education
Integrated Knowledge
Systems
Ilona Jerabek
Plumeus, Inc. /
Queendom.com
James Houran
TRUE.com
Abstract.
Compatibility tests are the foundation of many online
matchmaking services, but psychometric support for their use is ambiguous or
unavailable. This paper summarizes the unprecedented application of Rasch
scaling to assess the structure and validity of an online proprietary
compatibility test, termed the TRUE Compatibility Test (TCT). Contrary to
previous efforts at quantifying long-term, romantic compatibility, the TCT
integrates both the principles of similarity and complementarity of partners’
characteristics. The theoretical rationale of the measured constructs,
technical quality and validity of the test are outlined. Furthermore, the
findings are discussed with respect to the conceptualization and measurement of
relationship quality. It is argued that models of assortative mating in terms
of gross similarity or complementarity are oversimplifications and that a
schema or “couple-centered” approach is a more valid predictor of relationship
satisfaction and stability. Specifically, it appears that men and women have
different definitions of relationship quality. Thus irrespective of the
necessary but unquantifiable element of “romantic chemistry,” our research suggests
that couples with satisfying and stable relationships are distinguished by
their ability to integrate qualitatively different issues into the relationship
via complex mental processes.
Introduction
The Internet has become a standard fixture in our society, with communication being one of its most popular uses. Through extended communication on the Internet, many users have formed relationships with others online. However, research has only recently begun to address the subject of online relationship development (see e.g., Bonebrake, 2002; Wolak et al., 2003). Kiesler and Kraut (1999) discussed how the nature of online relationships varies, but it is clear that flirting and dating (Whitty, 2003, 2004) and other forms of social networking (Ahuvia & Adelman, 1992) constitute an important aspect of the Internet phenomenon.
In light of these trends, it is not surprising that there is an apparent increase in the use and societal acceptance of so-called “compatibility tests” offered by online matchmaking services (Houran et al., 2004). Compatibility testing typically refers to a method of pairing unfamiliar people for long-term, romantic relationships based on the demographics, stated personal preferences, and personality profiling of individuals within a candidate pool. This type of testing is somewhat different, and arguably more difficult, than programs such as PREPARE and ENRICH that assess existing couples on the critical tasks related to early marital adjustment (see e.g., Fowers & Olson, 1986). Unfortunately, evidence for many advertised compatibility tests is either blatantly missing or lacking scientific standards (Houran, 2004, Houran et al., 2004; cf. Thompson et al., 2005). However, we are aware of two notable exceptions. First, Wilson and Cousins (2003b) published in a peer-review journal their Wilson Relationship Compatibility Indicator (WRCI) test, which yields “compatibility quotients” for couples. This test is the foundation of the matchmaking service and website of Cybersuitors.com. Wilson and Cousins have shown that heterosexual couples’ scores on this test show significant and positive correlation (average r = .31, p < .01) with scores on the Marital Adjustment Test (Locke & Wallace, 1959).
The WRCI is based on the principle of homogamy (similarity of partners’ characteristics), as opposed to the principle of complementarity (dissimilarity) of partners’ characteristics. As reviewed by Wilson and Cousins (2003a, 2003b), and recently echoed in new research by Luo and Klohnen (2005), cross-sectional and longitudinal research both suggest that similarity (“birds of a feather flock together”) is a better predictor of relationship quality than complementarity (“opposites attract”). It is important to note that this conclusion is also a gross oversimplification. The degree of similarity observed depends on the particular individual-difference domain studied, with romantic partners showing strong similarity in age, political, and religious attitudes; moderate similarity in education, general intelligence, and values; and little or no similarity in personality characteristics (for reviews, see Klohnen & Mendelson, 1998; Watson et al., 2004). The second example of an evidence-based compatibility test concerns the matchmaking service and website of TRUE.com (formerly TRUEBeginnings). TRUE commissioned the development of a comprehensive, online compatibility test designed to be broader in scope than the WRCI or the PREPARE marital preparation inventory via an integration of the mixed literature on similarity and complementarity. Furthermore, it was desired that the test be applicable to both heterosexual and same-sex matching. The resulting product was called the TRUE Compatibility Test™ (TCT).
The Present Paper
This report provides technical information concerning the
TCT – summarized from the comprehensive Technical
Manual for the TRUE Compatibility Test (TRUE & Jerabek, 2004). This
online Manual spans nearly 100 pages
and is available to any interested party for full scrutiny at: http://www.true.com/images/tctmanual.pdf?svw=footer.
Unlike the WRCI and other advertised compatibility tests, we show that the TCT
is the first compatibility test offline or online with reliability and validity
as stringently defined in the 1999 edition of the Standards for Educational
and Psychological Testing as issued jointly by the American Educational
Research Association, the American Psychological Association, and the National
Council on Measurement in Education (AERA, APA, NCME, 2002).[1]
As such, this paper is part of an active research program initiated by TRUE to encourage the sharing of evidence and findings among professional
and academic psychologists. Moreover, this report is intended to support the
perception of TRUE and its contractors that there is an
increasing need to enhance and maintain the status of online relationship
research and cyberpsychology in general.
Accordingly, in a
first section we provide a detailed theoretical rationale behind the
construction of the TCT. This section describes the psychological and
interpersonal variables that are assessed by this instrument, while providing
sample questions and references to the academic literature that formed the
basis for the construction of the TCT. Additional information regarding the
contents of the TCT can be found in Appendix A of the online Manual. A following section describes
the psychometric rationale for the TCT provided by Rasch scaling techniques.
This section includes an overview of the mathematical and statistical
considerations that are involved in “scoring” the
TCT. Finally, we present a section that details Rasch analyses of the TCT data
of 11,576 individuals of the seventeen major factors of the TCT.[2]
These analyses include items’ model fit, the results of bias tests, and
validity evidence. Throughout, pertinent technical results are listed in
the Appendices to the online Manual.
A final section discusses the theoretical import of the TCT’s development and
validation for refining issues in conceptualizing and measuring relationship
quality.
Although great effort was made to be complete as possible in describing the TCT, including its reliability, validity, matching algorithms, theoretical rationale, and scoring methods, the TCT is a proprietary product of TRUE.com. To protect this product, the text of most items is omitted, and the analyses refer to the TCT items by number only. Similarly, to protect the identity of the items and factors, the latter are identified only by a number – i.e., it is not possible to connect items and factors. Finally, “adaptive”[3] (i.e., answer- or group-specific) items that are not answered by all TCT test takers were omitted from all psychometric analyses. This left a total of 218 items for analysis.
Overview of the TCT
The TCT was
constructed by the second author’s online psychological testing firm, Plumeus,
Inc. (www.Queendom.com). Drawing on a thorough literature review, the test was
designed to address 99 key variables that determine each test-taker’s
long-term, romantic compatibility with potential partners. For some of the
variables, complementary or opposite matches are deemed better; in others, a
similar match is deemed more ideal (see e.g., Dryer & Horowitz, 1997; Klohnen & Luo, 2003). The goal of the TCT is to pair
people appropriately with potential partners across as many relationship
variables as possible. The test is arranged by top-level areas (factors), 13
second-level, more specific factors (subfactors), and 65 third-level, narrow
characteristics (subscales) that make up these factors.
The TCT
contains a pool of 616 items, some of which are core (administered to everyone)
and some that are adaptive (presented dynamically only if the test-taker is
inconsistent in his/her responses for the core questions in that factor).[4] On the basis of his/her responses, the
test-taker receives a Feedback Report
(a profile of his/her personality, habits, and attitudes, and how they can
affect his/her romantic relationships), an Ideal
Partner Report (a description of who the most complementary partner would
be for him or her), and a Compatibility
Report that reveals in detail to what degree potential partners are
compatible with the test-taker. The
test-taker also receives advice and tips that are tailored to his/her
particular issues.
Overall Structure
The top-level
factors are the largest, most general variables. These factors cover a spectrum
of areas relevant to relationships, ranging from conflicts to sex life and
communication. In addition,
- The subfactors (second-level
factors) are the main building blocks for the TCT. The subfactors are complex
characteristics, made up of even more specific traits (subscales).
- Further, subscales were derived
by deconstructing the subfactors and considering what elements contribute
to them. For example, open-mindedness in a relationship (subfactor)
is comprised of tolerance of mood instability, tolerance for differences
in opinion, tolerance for goal differences and need for control
(subscales).
The subfactors formed the initial building blocks of the TCT – the main elements that were thought to be most important in the development of the test. Like the subscales, all subfactors are based on and supported by empirical research. In particular, to meet the criteria for inclusion, there needed to be strong evidence of the importance of each issue in relationship satisfaction or relationship stability (longevity). To ensure face validity, they also needed to be relevant in a common-sense fashion. For an explanation of what the more targeted subscales measure, refer to Appendix A of the online Manual.
Although the TCT matching algorithm must
necessarily remain proprietary, we note that it uses responses to certain
specific question to match people with particular tastes. For instance, test-takers that indicated
that romantic people are unattractive to them are not paired with hopeless
romantics. Throughout, the matching process is governed mainly by the larger
factors, i.e., item combinations having the greatest reliability.
In general, the TCT matching algorithms use a
compatibility matrix that includes:
·
compatibility
levels of individual traits using similarity, dissimilarity or complementarity
algorithms depending on the issue
·
interactions
between specific traits
·
gender-specific
weighting of traits
·
relative
importance weighting of traits
·
bidirectional
algorithms for computing the final TRUE Compatibility Index TM (TCI).
The TCI is a metric akin to Wilson and Cousin’s (2003a, 2003b) “Compatibility
Quotient.”
Table 1 lists some illustrative questions used in the TCT. Additional details can be found in the text, and the remaining factors are presented in Appendix A of the online Manual.
Table 1: Some Illustrative TCT Questions
|
|
Name |
Examples
of questions |
|
1) |
Comfort
with Vulnerability |
I find it ________ to say things like “I love
you”, and “I am happy I found you”. a)
Very
easy b)
Easy c)
Awkward d)
Difficult e)
Very
difficult I
give people the benefit of the doubt. a)
Completely
true b)
Sort
of true c)
Somewhat
true/somewhat false d)
Sort
of false e)
Completely
false |
|
2) |
Open-mindedness |
I appreciate the fact that my partner and I have
differences of opinion, because discussing them helps us grow as people. a)
Completely
agree b)
Mostly
agree c)
Somewhat
agree d)
Mostly
disagree e)
Completely
disagree I encourage my partner to work towards his/her
goals, even if I disagree with them. a)
Completely
agree b)
Mostly
agree c)
Somewhat
agree d)
Mostly
disagree e)
Completely
disagree |
|
3) |
Ability
to Communicate |
I
become absorbed in what I’m saying, and fail to notice if others are bored or
offended. a)
Almost
never b)
Rarely
c)
Sometimes
d)
Quite
often e)
Most
of the time I
try to be sensitive to the needs of others and anticipate their reactions to
my words and actions. a)
Always
true b)
Often
true c)
Sometimes
true d)
Rarely
true e)
Never
true |
|
4) |
Sexual
Prowess |
Sexual fantasies are natural. a)
Completely
agree b)
Mostly
agree c)
Somewhat
agree d)
Mostly
disagree e)
Completely
disagree Ideally,
how often would you like to have sex? a)
At
least once a day. b)
Two
to three times a week c)
Once
a week d)
Two
to three times a month Once a month or less |
|
5) |
Interaction
with Others |
You
are one of three equally deserving employees eligible for a big promotion at
work. How likely are you to think
that you will be the one chosen for the promotion? a)
Completely
unlikely b)
Unlikely c)
Somewhat
likely/somewhat unlikely d)
Likely e)
Highly
likely Spending
time with others wears me out. a)
Completely
untrue b)
Mostly
untrue c)
Somewhat
true/somewhat false d)
Mostly
true e)
Completely
true |
|
6) |
Social
Network |
I am very close with my family. a)
Completely
true b)
Mostly
true c)
Somewhat
true d)
Mostly
untrue e)
Completely
untrue Without my loved ones, I would be lost. a)
Completely
true b)
Mostly
true c)
Somewhat
true d)
Mostly
untrue e)
Completely
untrue |
|
7) |
Conscientiousness |
When
I commit to doing something: a)
I
forget about it. b)
I
do it when/if I get around to it. c)
I
get it done, unless something more important comes up. d)
I
get it done. When
it comes to orderliness, I’m: a)
A
complete slob. b)
A
bit of a slob. c)
Average. d)
A
bit of a neat freak. e)
An
utter neat freak. |
|
8) |
Integrity |
My
friends would tell you: a)
I’m
honest to a fault. b)
I’m
generally honest. c)
I
sometimes stretch the truth. d)
Not
to believe a word I say If
I am running late for an appointment, I: a)
Contact
the person/people I’m meeting to let them know. b)
Rush
but don’t call. c)
Get
there when I get there. |
|
9) |
Adventurousness |
I enjoy going with the flow and being playful. a)
Completely
true b)
Mostly
true c)
Somewhat
true d)
Mostly
untrue e)
Completely
untrue I am a creature of habit. a)
Completely
true b)
Mostly
true c)
Somewhat
true d)
Mostly
untrue e)
Completely
untrue |
|
10) |
Rigidity |
I
have a tendency to resist changing how I am used to doing things. a)
Completely
agree b)
Mostly
agree c)
Somewhat
agree d)
Mostly
disagree e)
Completely
disagree You
and your partner have a strong difference of opinion. Are you willing to let it go? a)
Yes,
I’ll drop it. b)
It
depends on how important the issue is. c)
No,
I’ll try to convince him/her to accept my point of view. d)
No,
I’ll insist that my partner accept my point of view. |
|
11) |
Dominance |
Even when I’m quite upset with my partner, it’s hard for me to
bring it up. a)
Most
of the time b)
Often c)
Sometimes d)
Rarely e)
Never I make sure that my partner hears my point of
view. a)
Most
of the time b)
Often c)
Sometimes d)
Rarely e)
Never |
|
12) |
Healthy
Attachment |
I get more attached to others than they seem to
get to me. a)
Completely
true b)
Mostly
true c)
Somewhat
true d)
Mostly
untrue e)
Completely
untrue I
need ______ reassurance from my partner about his/her feelings for me. a)
Constant b)
Frequent c)
Occasional d)
Rare e)
No |
|
13) |
Psychological
Strength |
People
tell me that my moods are unpredictable. a)
Quite
often b)
Often c)
Sometimes d)
Rarely e)
Never When
I’m presented with a problem, I’m able to develop an effective solution. a)
Almost
never b)
Rarely
c)
Sometimes
d)
Quite
often e)
Most
of the time |
Relationship
Variables
Communication Style. Several studies have shown that effective and compatible communication style is one of the pillars of relationships. Couples with ineffective or unconstructive communication are more likely to report relationship dissatisfaction and distress (Christensen & Shenk, 1991; Rogge & Bradbury, 1999). Having compatible communication skills improves a couple's chance at happiness. Many potential stumbling blocks in relationships can be overcome by communication; it is the greatest key to intimacy. In fact, lack of emotional closeness and feelings of alienation are the best predictors of depression in both men and women (Heim & Snyder, 1991). Reported relationship quality has been shown to be influenced by positive communication behaviors, such as spousal support, companionship, intimacy and friendship (Jerabek, 2003; Julien et al., 2003; Pasch et al., 1997; Pasch & Bradbury, 1998; Prager, 1995).
An important aspect of the Communication Style factor is open-mindedness, which is comprised of tolerance of mood instability, tolerance for differences in opinion, tolerance for goal differences and need for control. This construct measures how amenable the test-taker is to differing viewpoints, along with how willing s/he is to relinquish control. According to a study by Shackelford and Buss (1997), lack of openness in both men and women results in lower esteem for them on the part of their spouses.
In addition, self-disclosure has been shown to be a good predictor of relationship satisfaction, in both men and women (Hendrick et al., 1988). Self-disclosure requires comfort with vulnerability, which is based on Bowlby’s defensively separate construct in attachment theory (Bowlby, 1969, 1973). According to his theory, the defensively separate have a harder time becoming closer to others. Their relationships are characterized by less overall satisfaction, not to mention lower quality – they lack trust, and they experience more unpleasant emotions than positive ones (Meyer & Pilkonis, 2001; Simpson, 1990).
However, the amount of communication people desire in a romantic relationship differs greatly, both within a couple and between couples. Jerabek (2003) has demonstrated that the degree to which a relationship meets the person’s need to communicate is strongly correlated with self-reported relationship satisfaction. The TCT takes this issue into account and matches partners based on their preferences for connectedness in a relationship.
Accordingly, the Communication Style factor
encompasses all the above-mentioned factors, including ideas about how much
communication is needed in a relationship, which issues are worth discussing,
and to what extent emotions should be shared.
Other factors that contribute to overall communication style include
level of comfort with displays of emotion, self-disclosure, need for intimacy,
comfort with expressing and witnessing emotions, and willingness to be
vulnerable in a romantic relationship. Also included are the need for
intellectual discussions, general communication skills, sensitivity and tact,
open-mindedness in terms of the communication process, and tolerance for
differences in opinion and goals (Meyer & Pilkonis, 2001; Rogge &
Bradbury, 1999; Simpson, 1990).
Conflict Resolution. The ways that individuals approach and resolve conflict situations can greatly influence their likelihood for establishing successful relationships. Conflict resolution skills are essential to overall relationship satisfaction, and working on developing skills in this area can produce a significant improvement in the couple’s happiness (Jerabek, 2003; Markman et al., 1993). By the same token, problematic conflict resolution style (competitive, dominating, passive-aggressive, withdrawal or submissive) in one or both partners leads to marital distress (Goeke-Morey et al., 2003; Gottman et al., 1998; Gottman & Krokoff, 1989; Kurdek, 1993, 1996; Kurdek & Schmitt, 1986).
Shackelford and Buss (1997) showed that when couples
experience conflict in a variety of areas (specifically affection and
attention, jealousy, finances, sex, chores and control and dominance), spouses
feel less esteem for one another. As
conflicts are inevitable in long-term relationships, the ability to
negotiate solutions to a variety of issues in a non-threatening way is
essential for the very survival of the romantic bond (Bradbury, 1998).
Moreover, parental conflict has a negative impact on children’s
adjustment and can lead to their maladaptive behaviors (Cummings & Davies,
1994; Grych et al., 2000), and this is especially true for girls (Davies &
Lindsay, 2004). There are many
different ways of dealing with conflict, some more productive than others –
whether or not respondents have what it takes to resolve conflict is essential
to consider. In addition, some
individuals are more likely to get into conflicts than others; hence, this is
important to consider when pairing subjects.
Therefore, in addition to respondents’ conflict style,
the TCT matching algorithms further take into account their proneness to
conflict and willingness to resolve it, while assessing the impact
of the interactions of these factors.
Sex Life. While sexual satisfaction is far from being the single most important factor in relationship satisfaction (according to a Queendom.com poll, only 35% of respondents claim that great sex life is absolutely necessary), sexual intimacy is important to a certain degree in most couples (Jerabek, 2003; Kelly & Conley, 1987; Perrone & Worthington, 2001). Intimacy brings partners closer, and allows them to express their love for one another. However, people have different attitudes, experiences, and preferences related to sex, all of which can contribute to discord if either party is unwilling or unable to compromise.
Sexual attitudes and behaviors are fundamental to both sexual compatibility and feeling fulfilled in this arena (Kelly & Conley, 1987). Since expectations and desires with respect to frequency of sexual encounters vary widely across all age groups, the test-taker’s libido is assessed and matched with potential partners. Moreover, attitudes about what is acceptable sexual behavior and willingness to experiment have been shown substantial variability throughout the life span, within age groups, in both genders and within all sexual orientation categories (Queendom.com, 1999, 2000, 2001).
Kelly and Conley (1987) reported that sexual history influenced marital outcome in their study. Terman (1938) and Burgess and Wallin (1953) have shown that high levels of premarital sexual activity are associated with marital instability in men. In addition, sexual faithfulness helps build a sense of trust between partners, and by the same token, unfaithfulness can significantly tarnish it.
To ensure compatibility in all these areas, the Sex
Life factor covers libido and desired frequency of sexual encounters,
faithfulness, sexual experience and history, sexual attitudes, and sexual
behavior.
Social Life. The amount of time a person likes to spend socializing, with whom they prefer to socialize, and their chosen social activities are all important when it comes to choosing a satisfactory partner (Asendorpf & Wilpers, 1998; Jerabek, 2003; Shackelford & Buss, 1997).
Social skills are important for relationship success, romantic and otherwise. Lack of people skills in one partner can lead to awkwardness and uncomfortable social situations. In fact, Shackelford and Buss (1997) demonstrated that both men and women who are married to disagreeable partners have less esteem for their partners. In more general terms, studies have shown that agreeableness prevents conflict with opposite-sex peers (Asendorpf & Wilpers, 1998; Graziano et al., 1996). Similarly, negative and pessimistic attitudes and approach to life can be very taxing for couples (Gottman et al., 1998; Julien et al., 2003; Pasch et al., 1997; Schulz et al., 2004).
The amount of couple and individual social life outside of the relationship is an important consideration. Interpersonal differences in this area can be great, causing clashes between couples about how much time to spend on their own, by themselves, and socially with others. Disagreement about how often and with whom the partners should or should not socialize can lead to recurring conflicts, jealousy, resentment, pent-up frustration, and feelings of abandonment, rejection and injustice. Jerabek (2003) found a strong and positive correlation between satisfaction with couples’ social life and self-reported relationship satisfaction. Extroversion is an equally important consideration as this trait influences how much time one wants to spend in the company of others. An introvert’s need for time for oneself can clash with an extrovert’s need for company, leading to feelings of suffocation in one and rejection in the other. In addition, Asendorpf and Wilpers (1998) reported that sociability predicts falling in love, while shyness prevents it, mainly by limiting the shy person’s exposure to potential partners.
Social support from sources other than romantic partner is an important factor in a model predicting marital satisfaction (Perrone & Worthington, 2001). In addition, relying solely on one’s romantic partner for fulfillment of all emotional needs places a lot of pressure on this partner and can lead to unhealthy attachment and co-dependent behavior – all of which in turn result in relationship distress (Jerabek, 2000).
In sum, the Social Life factor includes factors such
as extroversion, social skills, agreeableness, positive attitude, sense of
humor, selflessness, support network of friends and family, and desire for
friendships outside of the relationship (both couple and individual).
Personal Characteristics. Questions about one’s identity, how one interacts with people, and the way of looking at the world are all important factors to take into consideration when it comes to finding a mate. A suitable partner will truly complement the other’s personality, and have a similar outlook on life. Couples with similar personalities tend to have more satisfying relationships (Robins et al., 2000). The personal characteristics factor measures a variety of personality factors, along with attitudes about a variety of issues.
Conscientiousness: The Conscientiousness subfactor includes the following subscales: adherence to routine, self-discipline, organization/planning, orderliness, and dependability / reliability. Conscientiousness plays out in every area of relationships. People who are conscientious are likely to be frustrated by a lower level of conscientiousness in their romantic partners. Also, high conscientiousness in men is related to increased esteem towards them by their wives (Shackelford & Buss, 1997).
Integrity: The integrity subfactor measures overall honesty of the subject, along with whether their behavior is trustworthy. It consists of dependability/reliability, loyalty, and honesty. Honesty and trustworthiness are two extremely important attributes that people desire in romantic partners (Fletcher et al., 1999). Establishing and maintaining trust is essential for continued commitment in a relationship (Wieselquist et al., 1999).
Adventurousness: Adventurousness is another trait that can have a negative impact on a mismatched couple. People scoring low on this trait are reluctant to try new things; they tend to be sedentary and prefer a routine. Highly adventurous people, on the other hand, are ready to take off at the drop of a hat, love to experience new things, thrive on change and resent routine. Research has shown that sharing novel and exciting activities prevents boredom and stagnancy in a relationship. Being adventurous together is a good thing for a relationship (Aron et al., 2000); however, pairing two people far apart on adventurousness can cause serious personality clashes in the relationship. The Adventurousness subfactor includes the following subscales: flexibility, open-mindedness, energy level and zest, spontaneity, and adherence to routine.
Rigidity. The rigidity construct is assessed by the following subscales: need for control, standards (other-oriented perfectionism), flexibility, open-mindedness, and adherence to routine. It was included because being able to adjust in order to achieve compromise with a partner is essential to relationships, and this ability is nearly absent in people high in rigidity. According to Weiselquist et al. (1999), pro-relationship acts, such as sacrificing needs and preferences and making accommodations for a partner, helps build relationship trust.
Dominance: The dominance subscale consists of assertiveness, tolerance for differences in opinion, tolerance for goal differences – support, and need for control. A number of studies have demonstrated that the complementarity theory holds for this factor - people who are generally dominant tend to get along better with people who are more submissive, and vice versa (Dryer & Horowitz, 1997). However, dominant / submissive couples are at risk of developing co-dependency problems and the submissive partners may tend to fail to achieve successful differentiation of their selves, which is fundamental to long-term intimacy (Bowen, 1978; Guerin et al., 1996; Kerr, 1985; Skowron, 2000; Titelman, 1998).
Attitudes and worldview: This complex subfactor includes assessment of a variety of issues that frequently cause problems in romantic relationships.
· Gender roles: The TCT includes an assessment of the test-taker’s beliefs and attitudes regarding this potentially explosive issue. Perceived equality between the partners factors into relationship satisfaction (Perrone & Worthington, 2001). One’s gender role attitudes are reflected in numerous areas, but all of them essentially boil down to power balance in the relationship, from decision making, child care, chores and errands to division of financial resources.
· Money attitudes: This subfactor measures the participant’s approach and attitude towards money. Arguments about whether to spend versus save money can be a big stumbling block. If one partner is unable to curb his or her spending habits, the other partner may be resentful. Importance of money is also included in this measure; how driven one is, how many hours one is willing to work, and how much one desires spending money on the trappings of wealth are all affected by the importance one places on money. Conflicts about money can be a major indicator of problems in marriage; couples that argue about money feel much less esteem for one another than couples that do not argue about money (Shackelford & Buss, 1997).
· Political and social attitudes: While standing on the opposite sides of left / right spectrum does not necessarily prevent partners from forming a successful bond, these attitudes, especially in their extreme form, and even more so if combined with intolerance, can cause major opinion clashes in the couple.
· Parenting style: Similar strategies and opinions about parenting are important when a couple decides to raise a child together. Parenting styles – measured by attitudes, approaches, amount of affection shown to the children and level of discipline used – are varied, and must be taken into consideration. When it comes to parenting, being a team when it comes to parenting is imperative, as inconsistencies will typically lead to adjustment problems and maladaptive behavior in children (Brody et al. 2003; Kim et al., 2003; Ruiz et al., 2002). Style differences can also cause difficulties in marital relations, specifically in terms of couple intimacy (O’Brien & Peyton, 2002).
· Relationship attitudes and dating philosophy: There are some issues that can actually make or break a relationship, such as differing levels of readiness to commit, different relationship values, and lack of consensus about whether the relationship will end in marriage or is just a short fling. Each individual enters into relationships with their own preferences and expectations. If fundamental differences do exist, a couple may find that they have to either compromise on important issues or look elsewhere (Gray-Little et al., 1996).
· Romantic attitudes: While some might argue that being romantic, attentive or chivalrous have little to do with long-lasting relationship satisfaction, the fact is that these attitudes are not just skin-deep. Surely, romantic gestures and passionate attentiveness are more frequently observed in the early states of courtship. Nevertheless, there is no denying that remembering anniversaries, breakfast in bed and little affectionate gifts can contribute to a lasting romance, maintenance of passion and feeling of being loved, which in turn have a major impact on relationship satisfaction (Bradbury et al., 2000; Jerabek, 2003).
Attachment Style. Some people prefer complete independence from their partner, while others rely on their partner for almost everything, from self-worth to personal identity to decision making. There are those who need independence, and others who prefer to be attached at the hip most of the time. It is crucial to know what a potential partner’s relationship style is like from the very beginning. Discrepancies in terms of attachment needs can lead to disappointment and conflict in the relationship (Christensen & Shenk, 1991; Simpson, 1990).
One
aspect of a problematic attachment style is dependency, an inability to
differentiate one’s self from partner.
Differentiation of self
in intense emotional bonds is essential for development of a healthy
relationship. It allows for greater
role flexibility and deeper intimate contact.
Partners who maintain their sense of self can tolerate differences of
opinion and are less emotionally reactive (Bowen, 1978; Kerr & Bowen,
1988). Conversely, partners in poorly differentiated marriages are less
emotionally mature, have a limited capacity for closeness and separateness, and
tend to sacrifice self-development and sense of personal identity to maintain
stability in the relationship (Bowen, 1978; Kerr & Bowen, 1988; Schnarch,
1997).
The TCT also assesses other issues that are related to attachment style and dependency problems, such as security in a relationship and jealousy. Fear of rejection and abandonment are commonplace in couples with attachment problems. Studies on sensitivity to rejection demonstrate that people who anxiously expect rejection tend to readily perceive its presence in ambiguous or insensitive behavior of others (Downey & Feldman, 1996). Research by Downey and Feldman (1996) shows that rejection-sensitive people and their partners experience dissatisfaction with their relationship.
In addition, the TCT includes several subscales that assess need for personal space (i.e. having a life separate from partner), need for privacy (i.e. understanding and respecting each other’s domain), expectations in terms of the amount of social life of the couple (couple friendships) and need to maintain one’s individual friendships (socializing with others without the partner present). People with problematic attachment styles frequently hold dysfunctional relationship cognitions, which are linked to relationship dissatisfaction (Baucom & Epstein, 1990; Fincham et al., 1990; Kurdek, 1992). Unrealistic expectations and idealistic assumptions about how relationships should work set the stage for disappointment and a sense of failure when things don’t go as smoothly as one may wish. For example, people with dysfunctional relationship cognitions think that successful couples should never have any disagreements, should want to spend all their free time together or should never be attracted to another person. They feel that people who love each other should not have any secrets, should not need any personal space, should share anything and everything and should not need any friends other than their partner. In other words, they want to be “one body, one soul.” Once they realize that this is not the case in their relationshp, they may panic and overreact to minor problems.
Stress Reaction. A relationship has the potential to be a great source of support in stressful time – yet, for those people that deal poorly with stress the potential deterioration of the relationship can only add more stress. The relationships of couples that have less productive reactions to stressful life events may suffer when such events occur (Cohan & Bradbury, 1997). In addition, negative stressful events during workday contribute to angry marital behavior in women and withdrawal in men (Schulz et al., 2004) and in general to negative marital interactions (Crouter et al., 1989; Gottman & Levenson, 1988). According to Larson and Richards (1994), minor daily stressors, such as chores, childcare, and errands have a major effect on the emotional lives of the partners and the nature of family relationship. While some authors argue that gender differences are somewhat overrated when it comes to dealing with stress (Aries, 1996; Brody, 1999), several studies have demonstrated that men tend to use withdrawal (both emotional and behavioral) as a coping mechanism, women are more likely to be critical, verbally confront their partners, and initiate conflict (Christensen & Heavey, 1990; Gottman & Levenson, 1988). Brody (1999) argued that marriage is one context in which women are more likely to express more anger than men. These gender differences appear to be more pronounced under stress.
Since reaction to stress is highly subjective and depends on the person’s coping skills, sense of self-efficacy and ability to deal with adversity on an emotional level, the TCT includes number of factors assessing these characteristics. In a study by Waldinger et al. (2004), the ability to correctly read emotions was linked with concurrent marital satisfaction as well as interviewer’s assessment of long-term relationship stability and adjustment. It has also been demonstrated that emotional intelligence has a profound impact on one’s level of functioning, social success and happiness in general (Jerabek, 1999). Therefore, the TCT includes an assessment of emotional intelligence.
The Psychological Strength subfactor includes
several aspects that address these issues: security in a relationship,
dependency, need for control, self-esteem and self-confidence, mood stability
(including anxiety, depression, anger control and moodiness), optimism and
positive attitude. This construct is
most similar to the “big five” notion of neuroticism. There is a consensus in the literature that neuroticism is a
negative predictor of marital satisfaction (Kelly & Conley, 1987;
Shackelford & Buss, 1997).
There is no doubt that dealing with unstable emotions
in a partner is difficult, often leading to marital problems. However, the relationship between depression
and marital distress is bi-directional.
For example, 50% of women who are experiencing relationship problems
report significant depressive symptoms (Weissman, 1987). In fact, studies have shown that emotional
distance and alienation predict depression for both sexes (Cano & O’Leary,
2000; Heim & Snyder, 1991). In
addition, neuroticism in one of the partners has been shown to be one of the
best predictors of marital distress and dissolution of the couple (Kurdek,
1997).
Negative emotional behavior (e.g., expressed anger,
sadness, or contempt) has also been shown to differentiate satisfied from
dissatisfied couples (Schaap et al., 1988).
Likwise, self-esteem has been shown to be a good predictor of
relationship satisfaction, especially in men (Bailey et al., 1987; Hendrick
& Hendrick, 1988).
Basic
Measurement Issues: Technical Quality of the TCT
Rasch Scaling
The Danish mathematician Georg Rasch (1960/1980)
identified the necessary and sufficient mathematical model for the
transformation of ordinal observations (e.g., sums of correct answers or rating
scales) into linear measures (Wright, & Stone, 1979; Fischer, 1995). This
model has been applied productively to educational tests for over 40 years,
including many state-issued achievement tests and well-known commercial tests
like the Stanford Achievement Test (Harcourt, 2004). Rasch scaling also forms
the basis for international comparison in education such as TIMMS (Mullis et
al., 2000) and PISA (Adams, & Wu, 2002), which comprised hundreds of
thousands of students from across the globe.
The Rasch model is increasingly used for other purposes as
well (for an overview, see, e.g., Bond & Fox, 2001), including applications
in clinical psychology (McCutcheon et al., 2002; Lange, Thalbourne et al.,
2000), psychiatry (Lange, Greyson et al., 2004; Lange, Thalbourne et al.,
2002), medicine (Lange, Donathan et al., 2002; Lange & Hughes, 2004), and
artificial intelligence (Lange, Greiff et al., 2004).
The major differences between successful Rasch modeling and the classical scaling approaches can be summarized by four “rules” (Embretson, 1999, p. 12, cf., Embretson, 1995):
1. The standard error of measurement differs between persons with different response patterns but generalizes across populations.
2. Shorter tests can be more reliable than longer tests.
3. Comparing tests forms across multiple forms is optimal when test difficulty levels vary across persons.
4. Unbiased estimates of item properties may be obtained from unrepresentative samples.
In other
words, the classical notion that all test scores are equally reliable is
abandoned in favor of local (i.e., level-specific) standard errors of estimate
(SE) – no longer is there a single index of score reliability. Also, longer
tests are not necessarily “better,” as – depending on the distribution of
respondents’ trait levels – many questions are guaranteed to be redundant.
Thus, by using items that best address respondents’ different trait levels
(i.e., by purposely using non-parallel forms) greater measurement
precision is obtained. In the extreme, items can be selected specifically
to optimize reliability (or, equivalently, minimize SE). When this is done in
an interactive computerized fashion, one speaks of Computer Adaptive Testing,
or CAT (see e.g., Wainer, 2000).
Basics. The Rasch scaling of binary (i.e., dichotomous) items assumes the form of a logistic regression model where each person and item is individually parameterized to derive the log odds of the probability P of observing an answer indicative of the trait under consideration. For binary items (i) and persons (n):
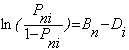 . (1)
. (1)
In the above, Pni reflects the
probability that person n will answer item i affirmatively, where
person n has trait level Bn and item i reflects
the trait amount Di. Note that the item and person parameters
share a common metric as defined by the left-hand side of Equation 1 – i.e.,
the log-odds of the probability Pni. Accordingly, all
quantities in the Rasch model are said to be expressed in logits.
Equation 1 shows that the Rasch model is additive in the
parameters (Bn) and (-Di). Thus, in
contrast to related models such as the two- and three-parameter logistic (cf.,
Fisher, 1995), the Rasch model meets the first requirement for interval
measurement – i.e., additivity (Michel, 1990).[5]
It follows from Fisher's principle of statistical sufficiency (see Wright &
Stone, 1979) that the maximum-likelihood of the parameter estimate for each
parameter occurs when the expected raw score corresponding to the parameter
estimate equals the observed raw score. Accordingly, raw scores are sufficient
statistics for the parameters B and D – indeed, these quantities
can be estimated independently of each other.
Rating Scales. The Rasch model has been extended to rating scales (Andrich, 1978) and partial-credit observations (Masters, 1982) for polytomous items, i.e., response formats where respondents select from two or more presumably ordered response categories. The rating scale and partial credit formulations both introduce “step” values {Fk} representing the boundaries between two adjacent rating categories k and k-1. To be precise, each Fk reflects the point at which the choices of categories k and k-1 are modeled to occur with equally probability. However, they differ with respect to the assumptions made concerning the item-dependency of the step values. In particular, the rating scale model assumes that the {Fk} are the same for all items under consideration, whereas the partial credit model allows the {Fk} to vary across items (see, e.g., Wright & Masters, 1982).
Figure 1
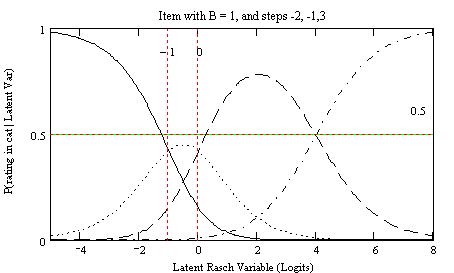
The TCT as described in the online Manual uses a hybrid of these two formulations that allows items’ step values to vary across different sub-groups (g) of items. In other words, it is assumed that items share the same step values within a particular sub-group, but these values are allowed to differ from the step values for other item sets. Accordingly, the group specific step values will be denoted as {Fgk}. Like the item and person parameters, the step values are additive, thus yielding the hybrid model:
![]() (2)
(2)
In the above:
·
Pnik is the probability of observing category k for
person n encountering item i.
·
Pni(k-1) is the probability
of observing category k-1
·
Fgk is the difficulty of being observed in category k
relative to category k-1, for an item in group g.
Solving for Pnik in Equation 2 (not shown, see, e.g., Wright & Masters, 1982) yields an explicit equation whose plot serves to illustrate the quantities defined above. For instance, Figure 1 above shows the Pnik (Y-axis) for –5 < Bn < 8, with Di = 1 and Fg1 = -2, Fg2 = -1, and Fg3 = 3. In this figure, Fg1 and Fg2 are shown at –1 and 0, respectively, as their values (i.e., -2, and –1) are relative to the item’s overall location (B, X-axis) – in this case, 1. Going from left to right, the curves in this figure reflect the probability of observing a particular rating 0, 1, 2, 3, given B. The reader can verify that the {Fgk} are located at the point where the probability of finding a response in two adjacent categories is identical (i.e., at the intersections of the curves). Thus, the {Fgk} reflect the categories’ interior boundaries.
It is noted that the rating-scale and the
partial-credit formulations are both special cases of Equation 2. The former
obtains when all items are in the same group, and the latter obtains when each
item defines its own separate group. Also, Equation 1 for binary items obtains
when rating scales with just two categories are used.
Further Generalization. Linacre (1989) generalized Equations 1 and 2 to a Many-Facet Rasch Model by allowing the left-hand side to be affected by the effects of additional independent variables (or, “Facets”) as well. In the simplest case respondents’ trait levels can be thought of as being affected by a single variable C (e.g., respondents’ age or gender) with levels j:
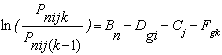 (3)
(3)
Note
that the additive properties of the model are maintained. In particular, raw
scores are sufficient statistics for the Bn, Di
and Cj, and the counts of observations in each category are
sufficient statistics for estimating the {Fk}.
Model Fit. All Rasch formulations support powerful quality-control fit
statistics for assessing the conformance of the data to the model (see Wright
& Stone, 1979). Practice indicates that the model is robust against many
forms of misfit, and typical perturbations in data tend to have little
influence on the measure estimates. Thus, while a few misfitting items may
introduce noise, the quality of measurement provided by the other items is
thereby little affected. A further feature of the data is its robustness
against missing data. Since the model is parameterized at the individual
observation level, estimates are obtained only from the data that has been
observed (assuming that “missing” is not in fact a response option). There is
no need to impute missing data, or to assume a particular form of the
distribution of parameters. Of course, missing data decrease the precision with
which parameters can be estimated.
In estimating the measures, the model acts as though the randomness in the data
is well behaved in accordance to the particular Rasch model being used. This is
not a blind assumption, however, because the quality control fit statistics can
be computed to report where, and to what extent, this requirement has not been
exactly met. For instance, for each response to item i by person n,
a standardized residual zni can be computed as the
difference between an observed datum and the probability estimate P of
its occurrence (e.g., as derived via Equations 1, 2, or 3) after
division by its standard deviation. Since such zs are
approximately normally distributed, unexpected results (e.g., observations with
|z| > 3) are easily identified.
The preceding forms the basis for computing the overall fit of the questions across respondents as quantified by their Outfit. For instance, the Outfit of item i over respondents n is:
![]() (4)
(4)
Since the summed z2 in Equation 4 define an approximate χ2 statistic with expected value n – 1, the Outfit statistic ranges from 0 to ∞, with an expected value of 1. Additionally, items’ Infit can be computed by weighting the terms in Equation 4 by the difference between the item and person locations (see Wright & Masters, 1982). Thus, the items’ Outfit is sensitive to deviations across the entire range of the latent Rasch variable, whereas their Infit mainly reflects localized inconsistencies.
Although the ideal Infit and Outfit values are 1, consistent with prevailing practice (see e.g., Bond, & Fox, 2001) values in the range 0.6 to 1.4 will be considered acceptable. Note that fit values exceeding 1 indicate the presence of unmodeled variation (i.e., the data are too noisy), whereas values smaller than 1 reflect the absence of modeled noise (i.e., the responses show greater determinism than is entailed by the model). The former is a more serious threat to model fit than the latter.
Differential Item and Test Functioning. Embretson’s (1999, p. 12, emphasis added) statement that “unbiased estimates of item properties may be obtained from unrepresentative samples” implies that items locations B should be invariant across sub-populations of the respondents. Recomputing the item locations Bi in samples from this population can check this assumption. When such checks reveal that the items’ locations systematically differ across sub-groups, we say that these items show Differential Item Function, or DIF. In the present context, age and gender are of particular interest because Lange, Houran et al. (2004) found that these variables yielded statistically significant DIF effects in a relationship-related context.
The finding of DIF
threatens construct validity since this implies that different sub-groups
assign different semantics to the underlying variable (for a discussion, see
Lange et al., 2001). The presence of DIF does not imply however that the
measurement of the latent variable is thereby seriously compromised – i.e.,
there need not be Differential Test Functioning (DTF). In particular, DIF
in some items may cancel that in others, thereby having little or no effect on
the estimated person parameters (for examples see e.g., Lange, Irwin et al.,
2000; McCutcheon et al., 2002). Unfortunately, DIF cancellation – and
hence the absence of DTF - is by no means guaranteed (cf., Lange,
Thalbourne et al., 2002; Lange, Houran et al., 2004) and should thus not be
taken for granted.
An effective means to
establish the absence of DTF is to determine whether the raw-score to
Rasch (R-to-R) measure conversions differ by more than these measures
standard errors of measurement. In the present research this is done
graphically by (a) plotting the R-to-R translation, together with the
local SEB (i.e., B + SEB) and
then (b) checking whether the sub-group specific R-to-R fall inside this
interval, except perhaps for the most extreme measures.[6]
If so, it has been established that sub-groups’ estimated measures show no
meaningful variation.
In the present context, we
focus on DTF related to respondents’ age and their own versus preferred
partner gender.
·
Age DTF is
assessed by comparing the R-to-R transformation for younger (age < 35
years) vs. older (age > 35 years) respondents.[7]
·
All four own vs. preferred
partner gender groups are considered. Thus, denoting male as M and
female as F, the four gender preference groups are FF, FM, MM, MF.
Parameter
Estimation. The parameters of the Rasch
models used here will be estimated using the versatile Winsteps software
(Linacre, 2004). This produce estimates of all model parameters in Equations 1
through 3 Joint Maximum Likelihood Estimation (JMLE) procedures. These
procedures are sufficiently efficient to analyze thousands of respondents and
items simultaneously, while allowing group-specific rating scale
parameterizations of the items. Winsteps also computes the item-total
correlations and the frequency of the ratings obtained for each item, as well
as the Infit and Outfit statistics discussed above.
Dimensionality.
A basic assumption underlying all of the preceding is that the items under
consideration define a single latent dimension. Unfortunately, it has long been
known (cf. Comrey, 1978; Panter et al., 1997) that standard item-level
factor analysis is inconclusive to establish unidimensionality (or
multi-dimensionality, for that matter).[8]
To make matters worse, it can be derived from statistical theory (cf. Stout,
1987, 2002) how multidimensionality may result from DIF – a finding that was
confirmed by computer simulations (Lange, Irwin et al., 2000).
The approach followed here to investigate items’
dimensionality is to analyze their residuals (see Equation 4) using
principal-component analysis because this addresses multidimensionality and DIF
simultaneously (cf. Linacre, 2004). The Winsteps software referred to above
incorporates such factor analyses as well.
Reliability. Within classical test theory "The reliability of any set of measurements is logically defined as the proportion of their variance that is true variance... We think of the total variance of a set of measures as being made up of two kinds of variance: true variance and error variance... The true measure is assumed to be the genuine value of whatever is being measured" (Guilford, 1965, p. 488). In other words,
![]()
![]() (5)
(5)
Thus, reliability (as embodied for instance in the KR-20 or coefficient alpha) is not an index of quality of the instrument over which it is computed, but this index rather quantifies the extent to which scores can be reproduced. The major problem with the preceding definition is that it:
- Treats raw-score sums as linear measures of the trait being measured.
- Must assume that observed scores have error without identifying a mechanism producing such error.
However, by explicitly modeling the stochastic nature of
each data point Xni Rasch scaling can identify
the source of the error variance. For instance, for the binary case,
![]() (6)
(6)
The
error variance of Rasch measures can thus be estimated by taking into account
the sum of the modeled variance of observations. Of course, this
"model" error variance requires the data to conform stochastically to
the Rasch model. Since there is always additional noise in the data,
simulations (Linacre, 1997) indicate that a more appropriate estimate of the
“real” error variance is:
“Real”
error variance = model variance * MAX(1.0, Infit mean-square) (7)
Accordingly, Rasch reliability indices tend to be lower than KR-20 and coefficient alpha. Equation 7 further implies that these indices always exceed the maximum reliability, thus indicating that a test has better measurement characteristics than it actually has. To be sure, KR-20 and coefficient alpha accurately reflect the reliability of raw scores. However, raw scores are not trait measures, but rather local, test-dependent rankings, and generalizing raw scores to test-independent, generalizable measures is simply not justified. This difference is increasingly recognized, and AERA/APA/NCME Standards recommends that the “error of measurement based on one approach should not be interpreted as interchangeable with another derived by a different technique” (Standard 2.5).
Item and Person Reliability. Although this is rarely done within the framework of classical test theory, the above applies equally to items and respondents. Thus, two types of reliability can be distinguished:
- person reliability, which addresses the overall error in the estimation of respondents’ trait levels (i.e., Bn)
- item reliability, which addresses the overall error in the estimation of the trait level implied by the items (i.e., Di).
In addition to providing an
impression of the adequacy of the size of the calibration sample, the latter is
important in situations where items are selected based on their locations on
the latent Rasch dimension (e.g., in test equating and computer adaptive
testing).
Item and Person Separation. While reliability indices are widely used, their interpretation is hindered by the fact that reproducibility is not a direct function of their magnitude. For instance, the difference between the two reliability coefficients 0.55 and 0.65 is far less than that between 0.85 and 0.95. For this reason, in Rasch scaling contexts the item and person reliability coefficients (R) are often expressed as separability indices (G):
![]() (8)
(8)
The separation index corresponds directly to the value of
Equation 5 above, and thus G ranges from 0 to ¥. The advantage of
using G rather than reliability indices is that they directly reflect
the number of statistically different performance strata that the test can
successfully identify within a particular sample. Thus, when G = 2.5
this indicates that the test succeeds in distinguishing at most ![]() = 2 different strata
of individuals.
= 2 different strata
of individuals.
Fisher (1992) takes a
slightly more liberal approach by defining the number of Discernible Strata
as (4 G + 1) / 3. The rationale for this definition is that the
functional range of typical measures is around 4 True SD. In most cases,
it is reasonable to inflate this by 1 RMSE to allow for the error in the
observed measures. If we then define a
significant difference between two measures as requiring a difference of at
least three RMSE, then there are ![]() significantly
different levels in the functional measurement range.
significantly
different levels in the functional measurement range.
Figure 2
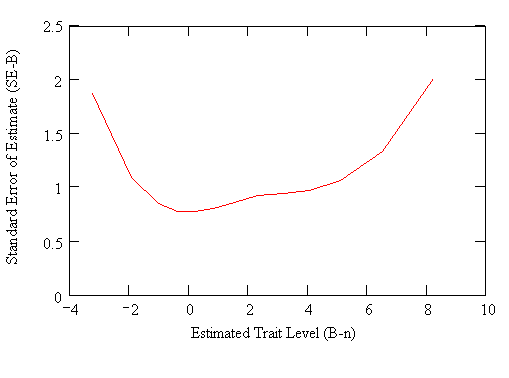
Local SEB. It has long been known that “reliability depends
upon the population measured as well as the measuring instrument...[hence one]
should speak of the reliability of a certain instrument applied to a certain
population under certain conditions” (Guilford, 1965, p. 439). Regardless
whether reliability or separation indices are used, the fact remains that the
standard error in estimating respondents’ trait levels varies across the latent
dimension – hence, measurement reliability cannot be captured adequately by a
single index, not even within a single
sample. In this context we note that Standard 2.1 states that “For each
total score, subscore, or combination of scores that is to be interpreted,
estimates of relevant reliabilities and standard errors of test measurement or
test information should be reported.”
Taken literally, this means that such information should be available for
each possible TCI measure, and this is the approach taken here.
In this context we note
that according to the Rasch rating scale model[9]
the reliability with which a person’s trait level can be assessed varies
directly with the number of step values Fgk that lie near
this person’s location Bn on the latent dimension (cf.,
Wright & Masters, 1982). As measures become increasingly extreme, then the
density of the step values must eventually decrease. Hence, the standard error SEB
associated with extreme (i.e., relative to the available Fgk)
person measures Bn is greater than the SEB
for Bn closer to the bulk of the Fgk. This
fact is illustrated in Figure 2, which shows a plot of the SEB
against the person measures Bn derived from a “test” consisting
of seven hypothetical rating scale items (Note: Additional plots based on
actual data will be given in Section 4 below).
4. Scaling Results
Respondents. Respondents. The scaling of the TCTTM
reported here is based on the responses of 11,576 users of TRUE.com’s online dating service. This
sample comprised 5769 men and 5807 women with a mean age of 35.3 years (Median
= 34, Range = 17 to 84 years). The distribution of respondents’ sexual
preferences – as inferred from their own gender and the preferred gender of
their possible partners [both M(ale) vs. F(emale)] – was: MM = 213, MF
= 5556, FM = 5508, FF = 299. Regardless of their fit to the Rasch
model (or lack thereof), no respondents were excluded from the analyses. The
frequency of the responses to the 218 selected questions’ various options are
listed in Appendix B in the online Manual.
Item Fit. To obtain a baseline, a series of
analyses were performed to determine the items’ fit to Equation 3 shown earlier
in Section 3 by treating 218 active non-adaptive items as a single scale.
Similar analyses were then performed over the items in the seventeen most
important subscales. For reasons that were discussed in the introduction, we
identify the items as well as the subscales by numeric tags only.
Appendix C
shows the locations Dgi of all 218 items, together with the
standard errors of estimate SEDi, as well as these items’ Infit,
Outfit, and Item-Total correlations.[10]
Rather surprisingly, and indicative of low dimensionality, the fit of the items
to a single Rasch dimension is quite good. Except for one item (Item 65),
all Outfit values fall within the standard acceptable range (i.e., 0.6
< Outfit < 1.4). Also, just 5 of the 218 items show negative Item-Total
correlations. However, the results of a principal-component analysis of the
item’s residuals (not shown) revealed substantial loadings on the first
residual factor. Accordingly, it is meaningful to consider additional factors.
Subfactors. The seventeen factors studied next were
labeled as Factors 10, 18, 19, 29, 35, 42, 52, 71, 72, 73, 75, 76, 82, 84, 85,
88, and 90.[11] The results
of the Rasch analyses of these factors are reported in Tables 2 through 18
below. It can be observed that the items show excellent fit to the Rasch model,
as indicated by the acceptable Outfit values and positive Item-Total
correlations (with very few exceptions, as is indicated by boldface entries).
Accordingly, the internal structure of these factors supports the assumption
that the items indeed define a latent dimension in accordance with the scaling
assumptions of the Rasch model.
Table 2: Factor 10
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0038 |
-0.93 |
0.01 |
0.92 |
0.92 |
0.36 |
|
I0072 |
-0.90 |
0.01 |
0.89 |
0.85 |
0.44 |
|
I0083 |
-0.81 |
0.01 |
0.91 |
0.88 |
0.43 |
|
I0077 |
-0.71 |
0.01 |
0.97 |
0.98 |
0.36 |
|
I0041 |
-0.60 |
0.01 |
0.88 |
0.86 |
0.46 |
|
I0058 |
-0.43 |
0.01 |
0.95 |
0.97 |
0.40 |
|
I0234 |
-0.16 |
0.02 |
1.02 |
0.99 |
0.14 |
|
I0201 |
0.06 |
0.01 |
0.96 |
0.96 |
0.49 |
|
I0170 |
0.53 |
0.01 |
1.02 |
1.51 |
0.29 |
|
I0090 |
0.62 |
0.01 |
1.14 |
1.16 |
0.30 |
|
I0049 |
1.01 |
0.01 |
1.16 |
1.33 |
0.26 |
|
I0048 |
2.31 |
0.02 |
1.10 |
1.24 |
0.00 |
Table 3: Factor 18
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0180 |
-1.07 |
0.01 |
1.00 |
1.02 |
0.25 |
|
I0203 |
-1.03 |
0.01 |
1.00 |
1.01 |
0.25 |
|
I0043 |
-0.87 |
0.01 |
1.06 |
1.26 |
0.17 |
|
I0053 |
-0.82 |
0.01 |
0.97 |
1.01 |
0.30 |
|
I0054 |
-0.82 |
0.01 |
0.98 |
1.03 |
0.29 |
|
I0130 |
-0.31 |
0.02 |
1.07 |
1.12 |
0.07 |
|
I0005 |
0.04 |
0.01 |
1.00 |
1.04 |
0.39 |
|
I0074 |
0.22 |
0.01 |
0.89 |
0.89 |
0.49 |
|
I0172 |
0.35 |
0.01 |
1.05 |
1.05 |
0.21 |
|
I0115 |
0.41 |
0.01 |
1.06 |
1.05 |
0.12 |
|
I0060 |
0.92 |
0.01 |
0.98 |
1.02 |
0.41 |
|
I0163 |
0.93 |
0.01 |
0.92 |
0.94 |
0.45 |
|
I0113 |
0.97 |
0.01 |
0.96 |
0.99 |
0.41 |
|
I0096 |
1.07 |
0.01 |
0.99 |
0.99 |
0.37 |
Table 4: Factor 19
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0053 |
-0.71 |
0.01 |
0.92 |
0.89 |
0.45 |
|
I0054 |
-0.71 |
0.01 |
0.94 |
0.91 |
0.43 |
|
I0040 |
-0.70 |
0.01 |
0.81 |
0.76 |
0.54 |
|
I0006 |
-0.52 |
0.01 |
0.85 |
0.83 |
0.52 |
|
I0129 |
-0.41 |
0.01 |
0.89 |
0.88 |
0.50 |
|
I0058 |
-0.36 |
0.01 |
0.83 |
0.83 |
0.55 |
|
I0151 |
-0.01 |
0.01 |
0.93 |
0.93 |
0.52 |
|
I0193 |
0.89 |
0.01 |
1.16 |
1.20 |
0.09 |
|
I0163 |
1.23 |
0.01 |
1.25 |
1.48 |
0.23 |
|
I0113 |
1.29 |
0.01 |
1.30 |
1.72 |
0.17 |
Table 5: Factor 29
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0138 |
-1.15 |
0.01 |
0.99 |
1.02 |
0.23 |
|
I0038 |
-1.13 |
0.01 |
1.00 |
1.08 |
0.21 |
|
I0147 |
-1.12 |
0.01 |
0.99 |
1.10 |
0.21 |
|
I0076 |
-1.01 |
0.01 |
1.02 |
1.07 |
0.22 |
|
I0088 |
-0.46 |
0.01 |
0.99 |
0.99 |
0.34 |
|
I0150 |
-0.39 |
0.01 |
1.07 |
1.11 |
0.19 |
|
I0201 |
-0.17 |
0.01 |
0.91 |
0.91 |
0.47 |
|
I0090 |
0.35 |
0.01 |
0.94 |
0.94 |
0.43 |
|
I0194 |
0.42 |
0.01 |
0.99 |
1.00 |
0.40 |
|
I0164 |
0.44 |
0.01 |
1.06 |
1.07 |
0.13 |
|
I0190 |
0.50 |
0.01 |
0.96 |
0.97 |
0.40 |
|
I0049 |
0.70 |
0.01 |
0.97 |
1.00 |
0.38 |
|
I0188 |
1.06 |
0.01 |
1.05 |
1.07 |
0.21 |
|
I0048 |
1.99 |
0.02 |
1.02 |
1.06 |
0.11 |
Table 6: Factor 35
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0064 |
-1.57 |
0.01 |
1.18 |
1.22 |
0.36 |
|
I0185 |
-0.85 |
0.01 |
0.93 |
0.96 |
0.50 |
|
I0057 |
0.11 |
0.11 |
1.11 |
1.16 |
0.54 |
|
I0194 |
0.11 |
0.01 |
0.84 |
0.80 |
0.65 |
|
I0066 |
0.40 |
0.13 |
0.72 |
0.68 |
0.69 |
|
I0104 |
0.50 |
0.01 |
0.82 |
0.76 |
0.63 |
|
I0143 |
0.52 |
0.01 |
0.79 |
0.71 |
0.64 |
|
I0091 |
0.79 |
0.01 |
0.90 |
0.78 |
0.57 |
Table 7: Factor 42
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0155 |
-0.76 |
0.01 |
0.99 |
1.00 |
0.43 |
|
I0020 |
-0.45 |
0.01 |
0.99 |
0.99 |
0.49 |
|
I0199 |
-0.45 |
0.01 |
0.98 |
0.98 |
0.50 |
|
I0102 |
-0.27 |
0.01 |
0.92 |
0.93 |
0.53 |
|
I0080 |
-0.01 |
0.01 |
1.00 |
1.01 |
0.50 |
|
I0193 |
0.38 |
0.01 |
1.15 |
1.19 |
0.16 |
|
I0163 |
0.75 |
0.01 |
0.94 |
0.93 |
0.51 |
|
I0113 |
0.81 |
0.01 |
0.97 |
0.95 |
0.49 |
Table 8: Factor 52
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0192 |
-0.82 |
0.02 |
0.96 |
0.96 |
0.30 |
|
I0039 |
-0.54 |
0.01 |
0.98 |
0.98 |
0.39 |
|
I0144 |
-0.35 |
0.01 |
0.96 |
0.96 |
0.34 |
|
I0155 |
-0.26 |
0.01 |
0.91 |
0.89 |
0.47 |
|
I0199 |
0.06 |
0.01 |
0.89 |
0.88 |
0.52 |
|
I0240 |
0.39 |
0.01 |
1.06 |
1.07 |
0.38 |
|
I0035 |
0.71 |
0.01 |
1.09 |
1.11 |
0.21 |
|
I0070 |
0.82 |
0.01 |
1.15 |
1.19 |
0.27 |
Table 9: Factor 71
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0162 |
-0.90 |
0.01 |
1.10 |
1.40 |
0.26 |
|
I0197 |
-0.72 |
0.01 |
1.01 |
0.99 |
0.25 |
|
I0119 |
-0.27 |
0.02 |
1.03 |
0.99 |
0.21 |
|
I0169 |
-0.15 |
0.10 |
1.11 |
1.07 |
0.46 |
|
I0135 |
0.23 |
0.01 |
0.83 |
0.82 |
0.58 |
|
I0196 |
0.24 |
0.02 |
1.02 |
1.08 |
0.13 |
|
I0105 |
0.25 |
0.01 |
1.01 |
1.04 |
0.44 |
|
I0002 |
0.63 |
0.01 |
1.04 |
1.12 |
0.39 |
|
I0136 |
0.69 |
0.01 |
0.87 |
0.86 |
0.52 |
Table 10: Factor 72
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0138 |
-1.09 |
0.01 |
0.97 |
0.97 |
0.25 |
|
I0038 |
-1.06 |
0.01 |
0.98 |
1.00 |
0.24 |
|
I0076 |
-0.95 |
0.01 |
0.99 |
1.01 |
0.25 |
|
I0237 |
-0.57 |
0.01 |
0.99 |
1.18 |
0.33 |
|
I0088 |
-0.41 |
0.01 |
1.00 |
0.99 |
0.32 |
|
I0110 |
-0.16 |
0.01 |
0.97 |
0.98 |
0.37 |
|
I0228 |
-0.14 |
0.02 |
0.99 |
1.00 |
0.15 |
|
I0238 |
0.23 |
0.01 |
1.00 |
1.08 |
0.19 |
|
I0170 |
0.36 |
0.01 |
0.98 |
1.40 |
0.26 |
|
I0164 |
0.47 |
0.01 |
1.00 |
1.00 |
0.21 |
|
I0049 |
0.72 |
0.01 |
1.00 |
1.06 |
0.31 |
|
I0163 |
0.77 |
0.01 |
0.97 |
1.01 |
0.35 |
|
I0136 |
0.92 |
0.01 |
0.99 |
1.12 |
0.30 |
|
I0152 |
0.92 |
0.01 |
0.99 |
1.15 |
0.30 |
Table 11: Factor 73
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0050 |
-0.74 |
0.01 |
1.02 |
1.01 |
0.27 |
|
I0141 |
-0.40 |
0.01 |
1.02 |
1.05 |
0.34 |
|
I0187 |
-0.33 |
0.01 |
1.00 |
1.04 |
0.44 |
|
I0098 |
-0.18 |
0.01 |
0.98 |
1.00 |
0.40 |
|
I0185 |
-0.17 |
0.01 |
1.01 |
1.01 |
0.33 |
|
I0184 |
0.03 |
0.01 |
1.10 |
1.10 |
0.09 |
|
I0055 |
0.51 |
0.01 |
0.86 |
0.86 |
0.55 |
|
I0103 |
0.56 |
0.01 |
0.87 |
0.87 |
0.53 |
|
I0084 |
0.71 |
0.01 |
1.14 |
1.13 |
0.03 |
Table 12: Factor 75
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0264 |
-1.46 |
0.02 |
1.09 |
1.27 |
0.36 |
|
I0263 |
-1.42 |
0.02 |
1.03 |
1.17 |
0.39 |
|
I0262 |
-1.11 |
0.01 |
0.81 |
0.73 |
0.57 |
|
I0261 |
-0.72 |
0.01 |
0.74 |
0.73 |
0.65 |
|
I0259 |
-0.32 |
0.01 |
0.64 |
0.62 |
0.74 |
|
I0260 |
-0.24 |
0.01 |
0.72 |
0.72 |
0.71 |
|
I0257 |
0.04 |
0.01 |
0.69 |
0.67 |
0.75 |
|
I0256 |
0.06 |
0.01 |
0.73 |
0.72 |
0.73 |
|
I0238 |
0.16 |
0.01 |
1.84 |
0.96 |
0.69 |
|
I0059 |
0.55 |
0.01 |
1.09 |
1.18 |
0.61 |
|
I0153 |
0.71 |
0.01 |
1.38 |
1.75 |
0.51 |
|
I0209 |
0.99 |
0.01 |
0.89 |
0.90 |
0.67 |
|
I0226 |
1.35 |
0.01 |
1.20 |
1.27 |
0.42 |
|
I0258 |
1.44 |
0.01 |
1.19 |
1.28 |
0.53 |
Table 13: Factor 76
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0180 |
-1.59 |
0.01 |
1.17 |
1.25 |
0.00 |
|
I0043 |
-1.39 |
0.01 |
1.23 |
1.57 |
-0.04 |
|
I0054 |
-1.35 |
0.01 |
1.22 |
1.46 |
0.00 |
|
I0187 |
-0.89 |
0.01 |
1.34 |
2.04 |
0.13 |
|
I0074 |
-0.30 |
0.01 |
0.91 |
0.91 |
0.48 |
|
I0080 |
-0.25 |
0.01 |
1.02 |
1.03 |
0.38 |
|
I0081 |
-0.23 |
0.01 |
0.88 |
0.89 |
0.50 |
|
I0059 |
-0.08 |
0.01 |
0.88 |
0.88 |
0.52 |
|
I0153 |
0.02 |
0.01 |
0.88 |
0.87 |
0.53 |
|
I0060 |
0.41 |
0.01 |
0.95 |
0.93 |
0.44 |
|
I0163 |
0.41 |
0.01 |
0.85 |
0.82 |
0.54 |
|
I0113 |
0.46 |
0.01 |
0.84 |
0.80 |
0.54 |
|
I0096 |
0.56 |
0.01 |
0.90 |
0.87 |
0.48 |
|
I0152 |
0.57 |
0.01 |
1.00 |
1.01 |
0.39 |
|
I0220 |
0.80 |
0.02 |
0.99 |
0.97 |
0.27 |
|
I0094 |
1.21 |
0.02 |
1.02 |
1.06 |
0.09 |
|
I0048 |
1.65 |
0.02 |
0.96 |
0.92 |
0.29 |
Table 14: Factor 82
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0204 |
-1.83 |
0.04 |
1.00 |
0.99 |
0.14 |
|
I0041 |
-0.35 |
0.01 |
0.95 |
0.94 |
0.44 |
|
I0019 |
-0.11 |
0.01 |
0.87 |
0.83 |
0.53 |
|
I0125 |
-0.02 |
0.01 |
1.04 |
1.05 |
0.31 |
|
I0234 |
0.12 |
0.02 |
1.01 |
0.96 |
0.20 |
|
I0202 |
0.25 |
0.01 |
0.88 |
0.88 |
0.57 |
|
I0205 |
0.79 |
0.01 |
1.05 |
1.06 |
0.27 |
|
I0190 |
1.15 |
0.01 |
1.16 |
1.24 |
0.35 |
Table 15: Factor 84
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0204 |
-1.59 |
0.04 |
1.00 |
1.00 |
0.15 |
|
I0078 |
-0.79 |
0.02 |
0.82 |
0.67 |
0.50 |
|
I0203 |
-0.51 |
0.01 |
0.89 |
0.88 |
0.47 |
|
I0189 |
-0.46 |
0.01 |
0.93 |
0.89 |
0.43 |
|
I0044 |
-0.39 |
0.01 |
0.87 |
0.82 |
0.50 |
|
I0114 |
-0.24 |
0.01 |
0.87 |
0.83 |
0.52 |
|
I0232 |
-0.23 |
0.01 |
0.88 |
0.83 |
0.50 |
|
I0041 |
-0.12 |
0.01 |
0.93 |
0.93 |
0.49 |
|
I0231 |
-0.07 |
0.01 |
0.87 |
0.85 |
0.54 |
|
I0227 |
0.09 |
0.01 |
0.90 |
0.89 |
0.51 |
|
I0019 |
0.12 |
0.01 |
1.07 |
1.07 |
0.42 |
|
I0125 |
0.21 |
0.01 |
1.08 |
1.09 |
0.26 |
|
I0205 |
1.03 |
0.01 |
1.15 |
1.18 |
0.15 |
|
I0190 |
1.39 |
0.01 |
1.46 |
1.67 |
0.11 |
|
I0015 |
1.55 |
0.02 |
1.15 |
1.20 |
0.09 |
Table 16: Factor 85
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0040 |
-0.55 |
0.01 |
0.83 |
0.75 |
0.53 |
|
I0064 |
-0.55 |
0.01 |
0.92 |
0.88 |
0.40 |
|
I0077 |
-0.52 |
0.01 |
0.87 |
0.83 |
0.48 |
|
I0039 |
-0.43 |
0.01 |
0.93 |
0.92 |
0.41 |
|
I0006 |
-0.39 |
0.01 |
0.85 |
0.81 |
0.51 |
|
I0129 |
-0.29 |
0.01 |
0.88 |
0.85 |
0.49 |
|
I0237 |
-0.24 |
0.01 |
1.08 |
1.11 |
0.36 |
|
I0160 |
-0.12 |
0.01 |
1.03 |
1.04 |
0.24 |
|
I0088 |
-0.06 |
0.01 |
1.04 |
1.04 |
0.33 |
|
I0151 |
0.07 |
0.01 |
0.93 |
0.94 |
0.45 |
|
I0222 |
0.33 |
0.01 |
1.14 |
1.34 |
0.23 |
|
I0075 |
0.56 |
0.01 |
1.32 |
1.38 |
0.09 |
|
I0238 |
0.59 |
0.01 |
0.99 |
0.99 |
0.26 |
|
I0069 |
1.61 |
0.01 |
1.17 |
1.33 |
0.00 |
Table 17: Factor 88
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0204 |
-2.12 |
0.04 |
1.00 |
1.01 |
0.10 |
|
I0232 |
-0.72 |
0.01 |
1.03 |
1.10 |
0.27 |
|
I0001 |
-0.41 |
0.01 |
0.99 |
1.00 |
0.36 |
|
I0019 |
-0.39 |
0.01 |
0.99 |
1.01 |
0.37 |
|
I0205 |
0.43 |
0.01 |
1.02 |
1.02 |
0.23 |
|
I0153 |
0.62 |
0.01 |
0.98 |
1.00 |
0.45 |
|
I0194 |
0.68 |
0.01 |
0.94 |
0.94 |
0.48 |
|
I0212 |
0.86 |
0.01 |
1.02 |
1.03 |
0.41 |
|
I0113 |
1.06 |
0.01 |
1.00 |
1.04 |
0.38 |
Table 18: Factor 90
|
Item |
Di |
SED |
Infit |
Outfit |
ritem-tot |
|
I0117 |
-1.15 |
0.01 |
0.99 |
1.25 |
0.32 |
|
I0118 |
-0.83 |
0.02 |
0.92 |
0.91 |
0.40 |
|
I0187 |
-0.65 |
0.01 |
0.86 |
0.85 |
0.55 |
|
I0197 |
-0.57 |
0.01 |
1.04 |
1.05 |
0.19 |
|
I0119 |
-0.10 |
0.02 |
0.90 |
0.81 |
0.42 |
|
I0196 |
0.40 |
0.02 |
0.95 |
0.91 |
0.29 |
|
I0120 |
0.41 |
0.02 |
0.96 |
0.90 |
0.28 |
|
I0105 |
0.45 |
0.01 |
1.00 |
1.06 |
0.44 |
|
I0002 |
0.80 |
0.01 |
1.23 |
2.49 |
0.10 |
|
I0094 |
1.49 |
0.02 |
1.02 |
1.02 |
0.15 |
Figure 3
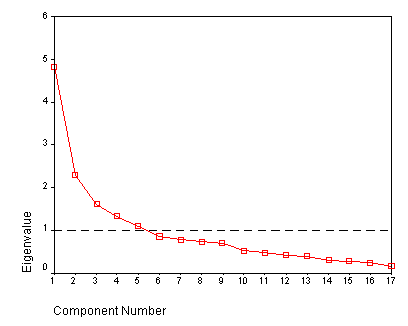
Respondents’ measures on
each of the 17 subscales were subjected to standard factor analysis. Consistent
with the analysis of items’ residuals, the plot of the magnitudes of the
components’ eigenvalues shown in Figure 3 shows clear evidence of
multi-dimensionality as several eigenvalues exceed 1.
Differential Test
Functioning. To assess whether the
seventeen factors suffer from DTF related to respondents’ sexual
orientation and age, separate raw sum to Rasch transformations were computed
for the four MM, MF, FF, and FM groups, as well as for Younger and
Older respondents. The results are shown pair wise in Figures 4 through 37
(i.e., the sexual orientation and age graphs for each factor are shown on a
single page). The error bands (+ 1 SEB) are relative
to the R-to-R derived for all respondents combined.
As is indicated by an
asterisk (*) in the titles of the graphs below, sexual orientation DTF
could not fully be assessed for four of the factors given the relatively small
numbers of MM and FF respondents.[12]
However, it is clear that the R-to-R values for the available subgroups
all fall inside the error band of the total group R-to-R for each of the
factors. In other words, there is no evidence that the Rasch measures show
systematic bias due to respondents’ age or sexual orientation.
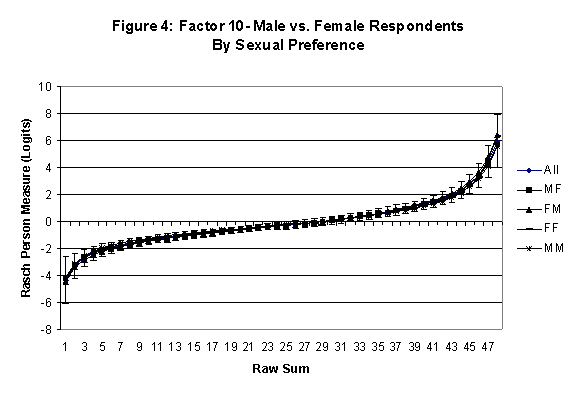
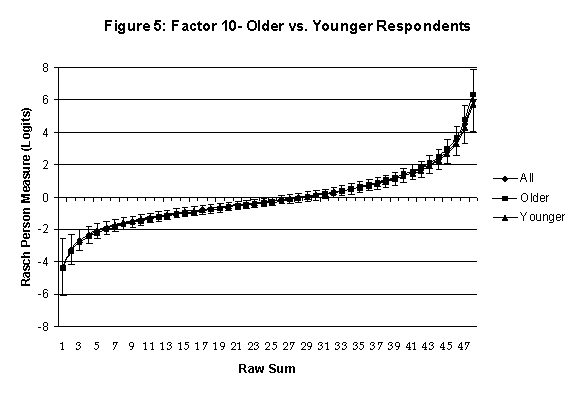
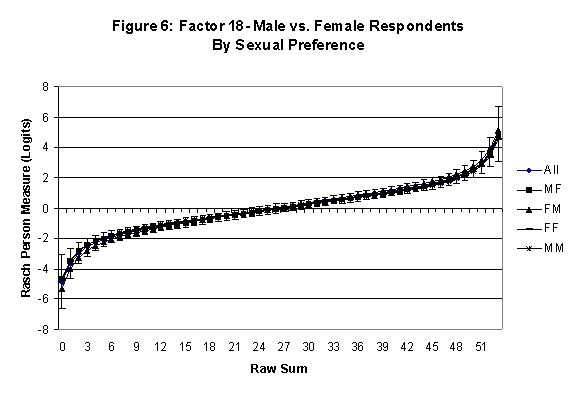
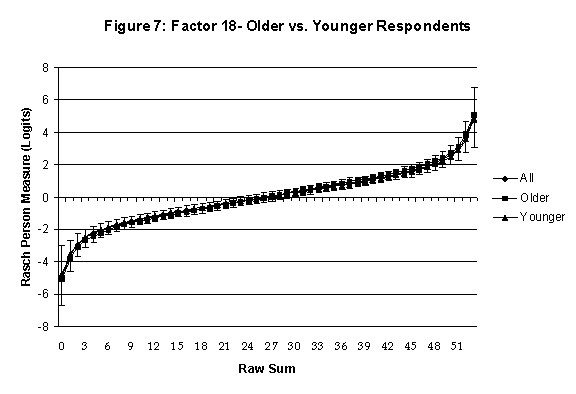
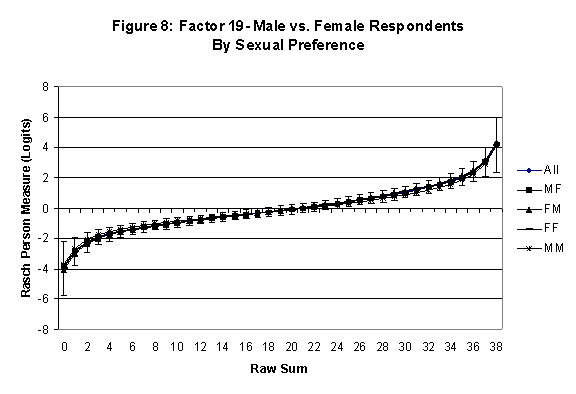
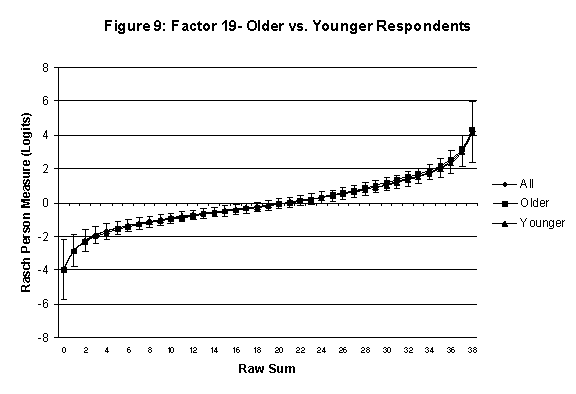
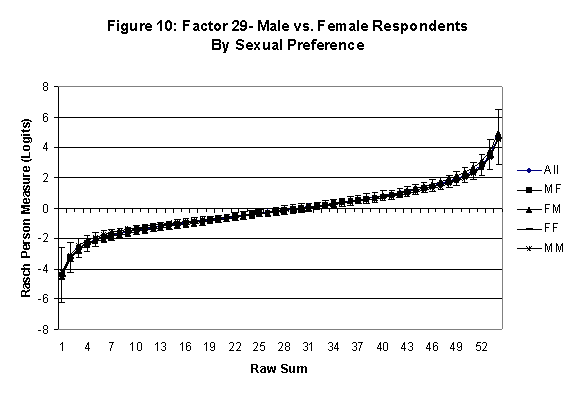
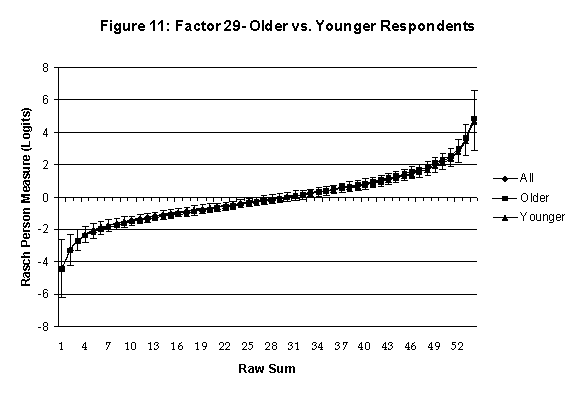
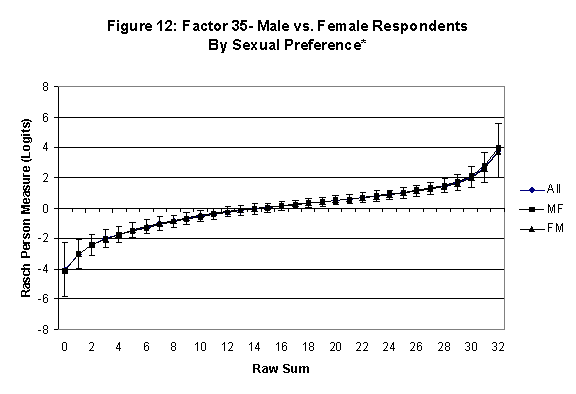
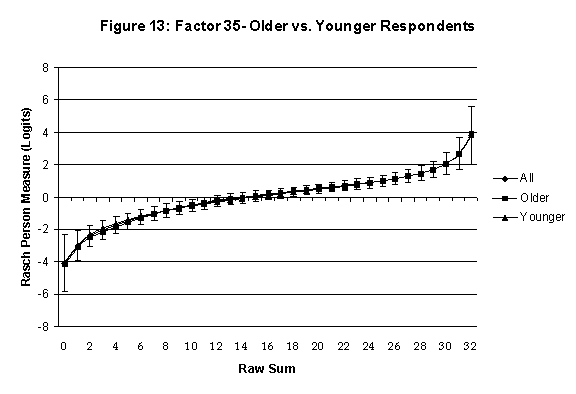
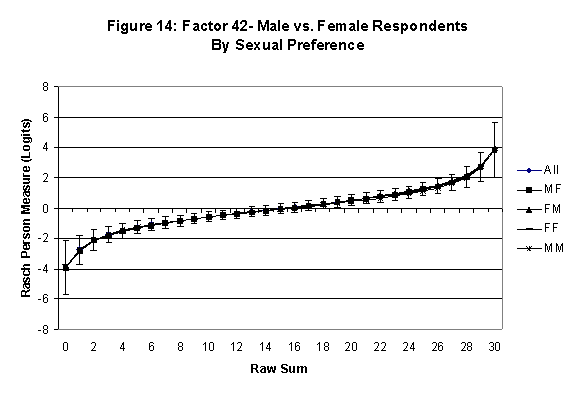
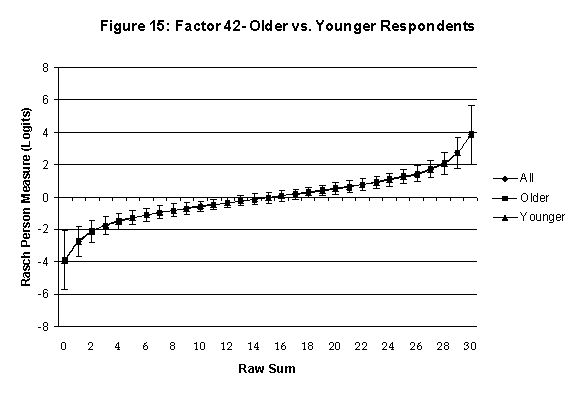
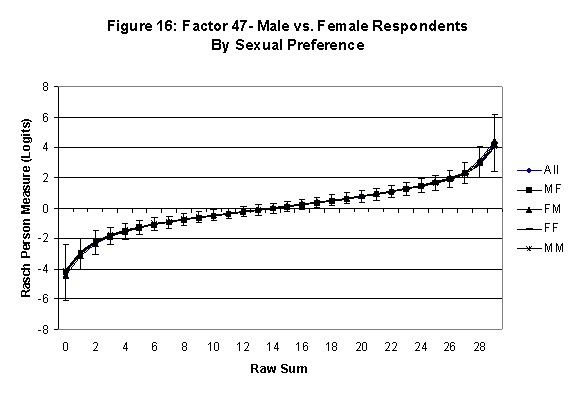
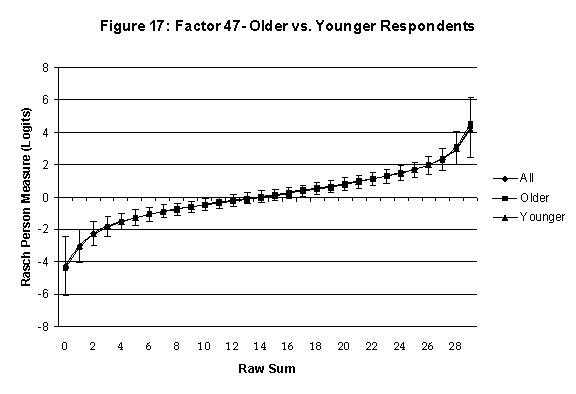
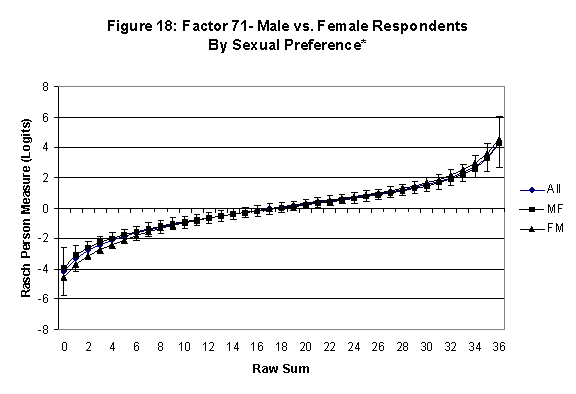
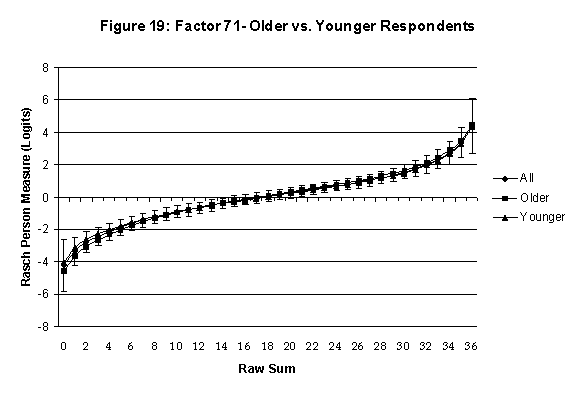
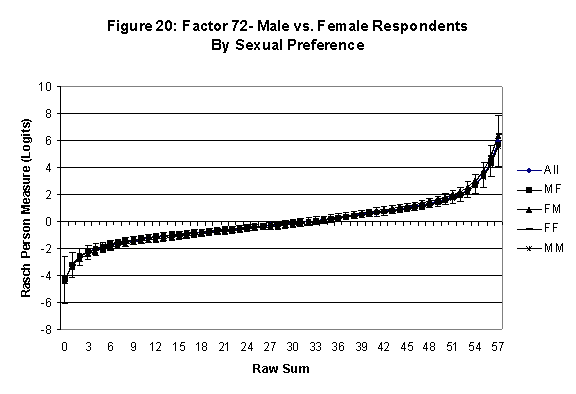
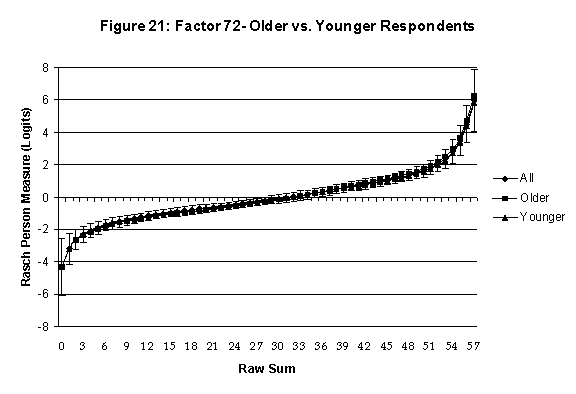
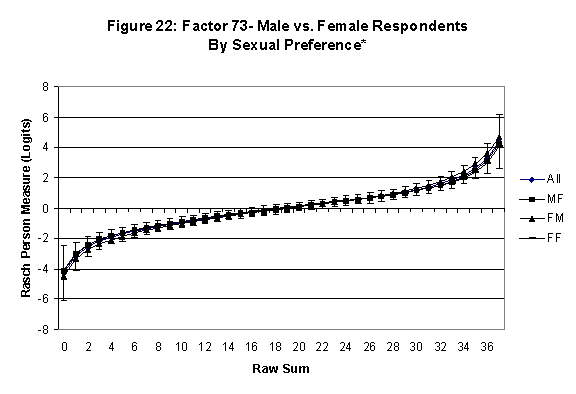
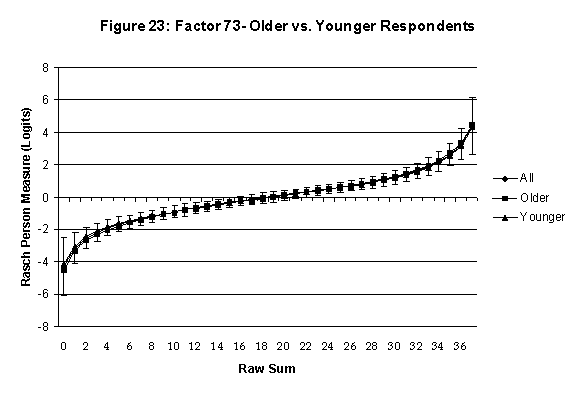
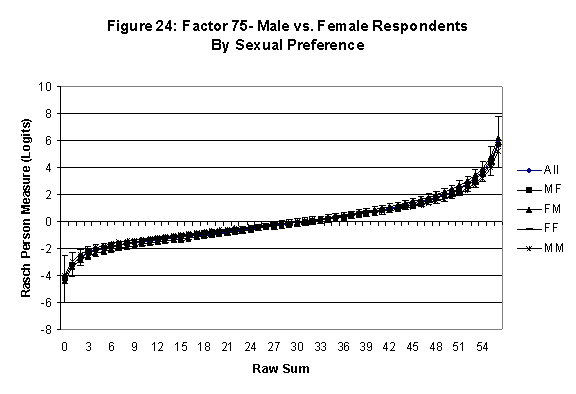
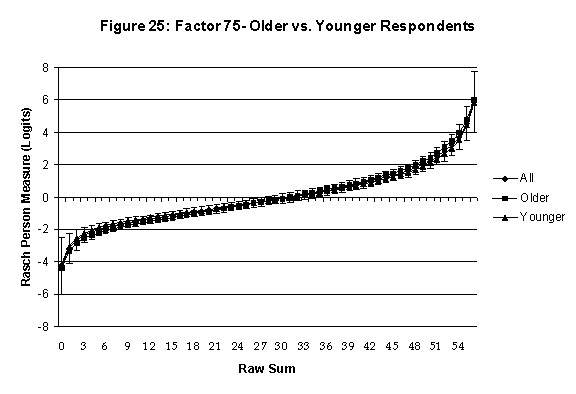
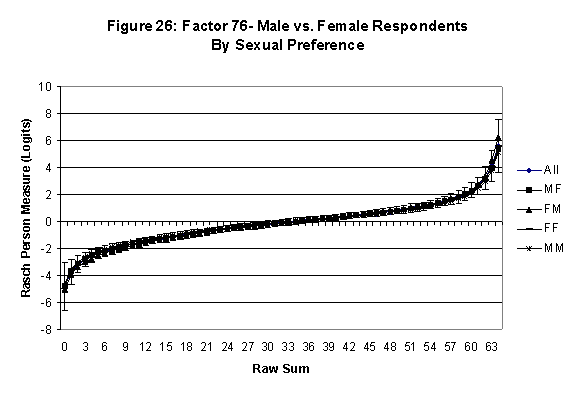
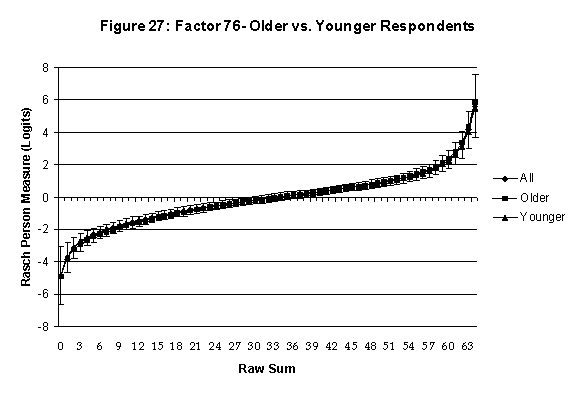
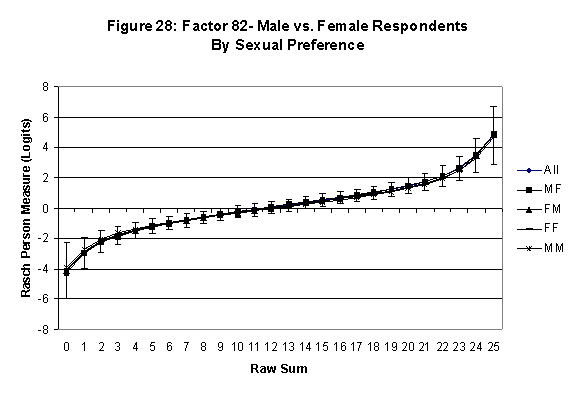
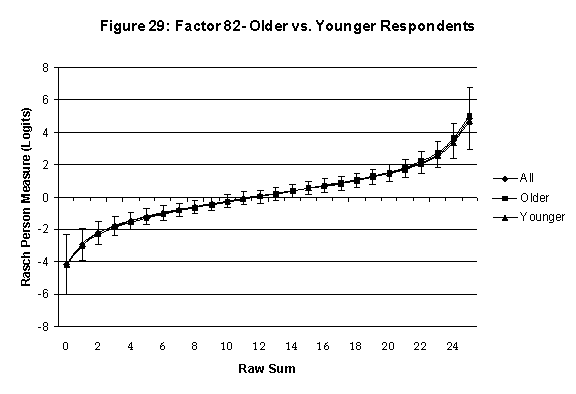
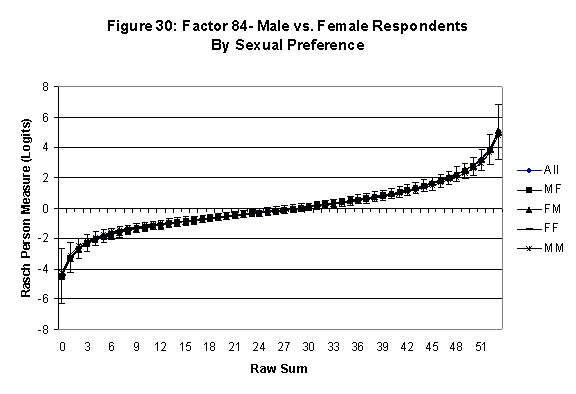
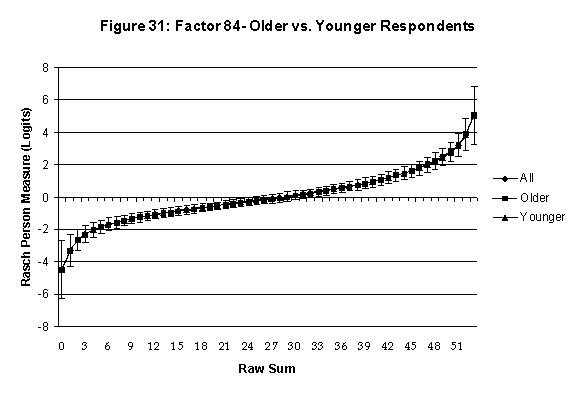
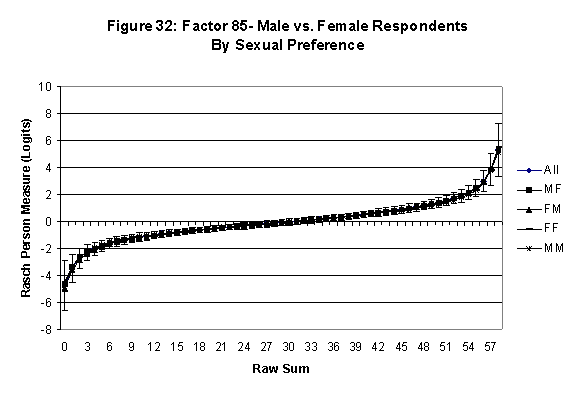
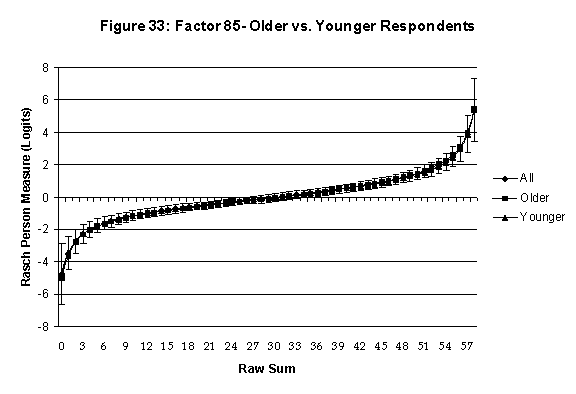
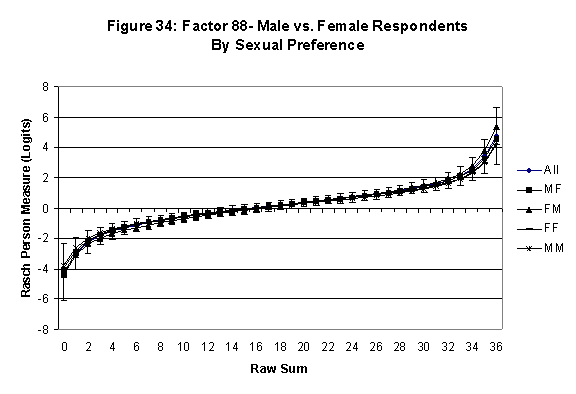
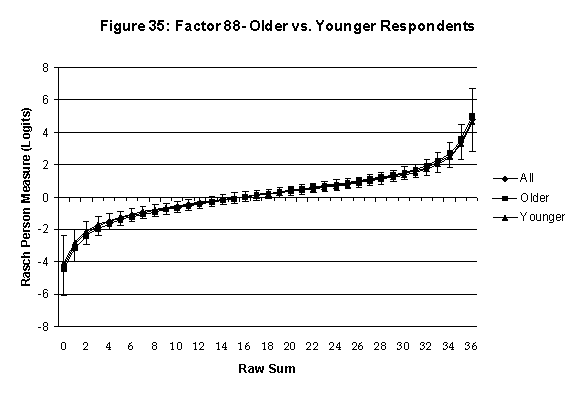
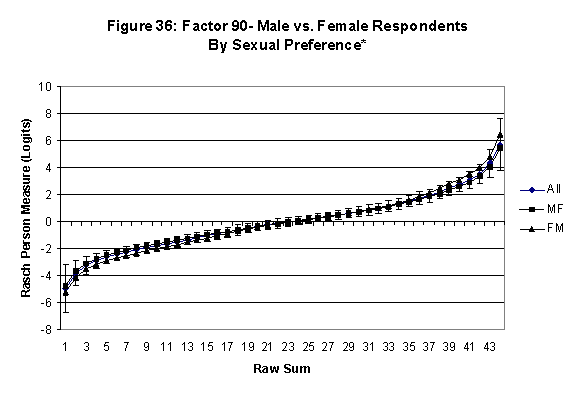
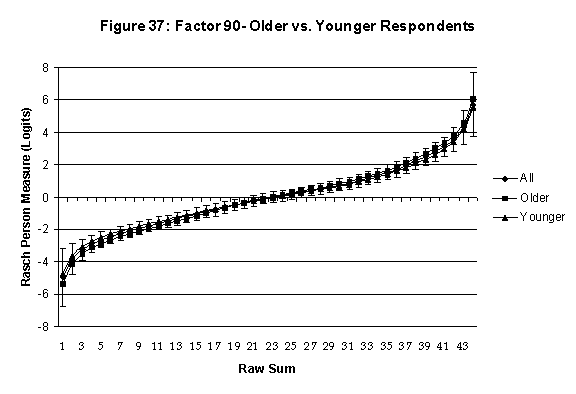
Reliability. Given the absence of DTF, the error bands in
Figures 4 through 37 may be assumed to give accurate estimates of the local SEB
for each of the factors. Note that, for reasons discussed in Section 3, the
size of the error bands B + SEB increases for more extreme
person measures and raw sums.
In addition, for each of
the seventeen factors Table 19 lists the Rasch reliability indices as well as
the separation values (G) for the items as well as the respondents. As
was noted earlier, the person reliability corresponds most closely to the
reliability estimate provided by Coefficient
Alpha (or KR-20) within
the framework of classical test theory. However, due to the more realistic
error assumptions being made, the value of the Rasch reliability coefficients
tends to be lower than overall reliability estimates obtained within the
classical framework.
Table 19: Item and person Reliability and Separation (G)
estimates
|
|
|
|
|
|
|
|
|
Persons |
|
Items |
||
|
Item Set |
Separation |
Reliability |
|
Separation |
Reliability |
|
All Items |
2.25 |
0.84 |
|
27.75 |
1.00 |
|
Factor 10 |
0.84 |
0.41 |
|
75.79 |
1.00 |
|
Factor 18 |
0.80 |
0.39 |
|
69.52 |
1.00 |
|
Factor 19 |
1.06 |
0.53 |
|
74.71 |
1.00 |
|
Factor 29 |
0.76 |
0.37 |
|
80.37 |
1.00 |
|
Factor 35 |
1.01 |
0.50 |
|
12.29 |
0.99 |
|
Factor 42 |
1.11 |
0.55 |
|
53.06 |
1.00 |
|
Factor 47 |
0.51 |
0.21 |
|
51.82 |
1.00 |
|
Factor 71 |
0.51 |
0.21 |
|
14.40 |
1.00 |
|
Factor 72 |
0.52 |
0.21 |
|
64.44 |
1.00 |
|
Factor 73 |
0.67 |
0.31 |
|
47.95 |
1.00 |
|
Factor 75 |
2.40 |
0.85 |
|
80.82 |
1.00 |
|
Factor 76 |
1.22 |
0.60 |
|
76.64 |
1.00 |
|
Factor 82 |
0.66 |
0.31 |
|
45.47 |
1.00 |
|
Factor 84 |
1.13 |
0.53 |
|
50.45 |
1.00 |
|
Factor 85 |
0.85 |
0.42 |
|
61.15 |
1.00 |
|
Factor 88 |
0.67 |
0.31 |
|
58.44 |
1.00 |
|
Factor 90 |
0.66 |
0.31 |
|
48.65 |
1.00 |
Note that the Rasch
reliability coefficients of the person measures produced by some of the
subscales are rather small (e.g., Factors 47, 71, 72, and 73). It should be
kept in mind, however, that these subscales are not used in isolation, but
rather that these contribute jointly to the matching process. Also,
within the TCT matching algorithm, less reliable subscales do not
form the decisive piece of information to match two individuals.
Not surprisingly given the
sample size, the reliability of the item locations is considerable. Thus, their
locations are known with high precision, thereby providing a sound basis for
future expansion of the TCT.
Preliminary
Validity Data for the TCT
Compatibility researchers (Fowers & Olson, 1986; Houran et al., 2004; Wilson & Cousins, 2002b) have conceded that longitudinal designs are needed to fully assess the efficacy of offline or online matchmaking tests. Yet, cross-sectional research on relationship satisfaction and stability can provide important preliminary data in support of a test’s validity.
To assess the
predictive validity of the TCT a separate study using 1101 married individuals,
including 112 couples was conducted (Lange Houran et al., 2004, Lange et al.,
submitted). This study is described in its entirety in Appendix D of the online
Manual. However, we summarize the
major findings below.
·
The Pearson correlation
between respondents’ satisfaction and compatibility measures is highly
significant (r = 0.26, p
< .001), thus supporting the notion that these variables form two
different factors. This correlation rises to 0.46 when corrected for
attenuation. Note that this effect size exceeds the validity findings reported
by Wilson and Cousins (2003) for the WRCI measure of compatibility. Thus, there
is solid evidence that couple similarity is associated with greater marital
satisfaction.
·
Yet, these two variables
should not be treated as identical because a two-dimensional Rasch model in
which the marital satisfaction and complementarity items are treated as
separate factors provides significantly better fit than does a one-dimensional
model comprising all items simultaneously (c23 = 1501.52, p <
.001).
·
Consistent with the
complementarity hypothesis, the level of satisfaction produces powerful
item-shifts (DIF). In
particular, those in the High satisfaction group disproportionately endorse
items that address couples’ division of responsibility, dealing with stress,
conflict resolution, and values as a couple. Of course, it is equivalent to say
that those Low in satisfaction are particularly dissatisfied with these issues. Surprisingly, the High group is
less satisfied with respect to value differences between partners than is
expected – and a large difference between this item’s location in the Low and
High groups is observed (1.22 Logits,
SEdif = 0.10, z = 11.61). Although direct evidence is
lacking, we hypothesize that this is because differences in personal values are
difficult to resolve by behavioral accommodation.
·
Extremely powerful
item-shifts (DIF) occur between
the Low and High satisfaction groups as defined earlier as the item locations
in these groups differ by at least 0.49 Logits
(all shifts are statistically significant, p < .01, 2-sided). The findings indicate that respondents’
patterns of complementarity ratings differ greatly with their marital
satisfaction. Specifically, those most satisfied in their marriages report the
lowest complementarity with their partners with respect to spending and saving
money. However, respondents in the Low satisfaction group report maximum lack
of complementarity with respect to sexual issues and parenting. In other words
– and perhaps not surprisingly so – dissatisfaction in marriage quickly
manifests itself as a lack of complementarity with respect to sexual and
parenting issues.
·
Location shifts in the
complementarity items due to differences in satisfaction are sufficiently
strong to distort measurement. In the present sample this means that over 40%
of the respondents would receive significantly different Rasch measures as
derived from the Low vs. High satisfaction translation functions.
Interestingly, the estimated person measures Rr for a raw sum score of 24 (1.11 Logits), derived for the Low
satisfaction groups exceeds the estimate (1.03 Logits) for a raw sum score of 26 as derived from the High
group’s data. Thus, the satisfaction related item-shifts are sufficiently large
to introduce measurement distortions at the ordinal level as well.
·
A multivariate analysis
of variance of the satisfaction and complementarity variables by Sex showed a
multivariate main effect (F2,1098
= 7.44, p < 0.001). Subsequent univariate analyses of
variance (ANOVA) indicated that Sex had a significant effect on satisfaction as
men expressed greater overall marital satisfaction than did women (MMen = 1.76 vs. MWomen
= 1.38 Logits, F1,1099 = 14.22, p < .001, MSe =
2.65 Logits). By contrast, women and men’s complementarity appears to be
highly similar (MMen = 1.35
vs. MWomen = 1.33 Logits, F1,1099 = 0.05, p >
0.50).
·
DIF effects may seriously affect latent variables’
quantitative properties. Moreover, statistical theory (Stout, 1987) and
computer simulations alike (Lange et al., 2000) indicate that item shifts may
create spurious factor analytic structures. Accordingly, it is no longer
obvious that widely cited results within the literature of assortative mating
(historical or current) should be accepted at face value. For example, it seems
likely that the notion of love consisting to varying extents of Romantic
Dependency, Communicative Intimacy, Physical Arousal, Respect, and Romantic
Compatibility (Critelli et al., 1986) might well vary depending on partners’
overall relationship satisfaction. Instead, consistent with Masuda’s (2003)
recent review, we suspect that Erotic and Companionate Love are the major
qualitative components, since these most resemble complementarity and
satisfaction, respectively. Finally, as is important for the increasing
popularity of online matchmaking businesses, we note the findings of
qualitative differences cast serious doubts on simple formulaic prescriptions
for romantic compatibility and relationship success (cf. Hoffman & Weiner,
2003; Wilson & Cousins, 2003b). Thus, TRUE’s decision to incorporate non-linear elements into its
matching algorithms is warranted and follows on the theoretical foundation established
by Gottman et al (2002).
Summary: Relation to
AERA/APA/NCME Test Construction Standards
Here we summarize how the evidence reported in the preceding sections pertains to the standards set forth in the 1999 Standards for Educational and Psychological Testing as issued jointly by the American Educational Research Association, the American Psychological Association, and the National Council on Measurement in Education (AERA, APA, & NCME, 2002).
The following summarizes the AERA / APA / NCME standards together with a summary of the evidence pertaining to each standard as described in this manual. The applicable Validity and Reliability Standards are shown separately in Tables 20 and 21, respectively.
Table 20: Applicable AERA / APA / NCME Validity Standards
|
Applicable Standard[13] |
Summary, or reference
to section within this manual |
|
1.1 Provide rationale for use
of test scores, interpretation, and theory. |
See Section 2, Section 5, and
Appendix C (online Manual). |
|
1.2 Define interpretation,
intended population and construct. |
Online daters, evident from
context. |
|
1.5 Sample composition for
validation |
Different by necessity. See
Section 5, Appendix C (online Manual).. |
|
1.6 Appropriateness of test
content, procedures. |
Content: Table 1, Appendix A
(online Manual). Validation used
online method only. |
|
1.10 Interpretation of
specific items |
Matching based exclusively on
factors and subfactors comprising several items. |
|
1.12 Rationale for composite
or difference scores. |
Rasch scaling. See Section 2. |
|
1.13 Describe conditions under
which validation data were collected. |
See Section 5, Appendix C
(online Manual). Validation is
based on data that was gathered online. |
|
1.14 Rationale and measurement
of “other” variables |
Simple classification
demographic variables are used whose validity seems evident are used. The TCT
showed no DTF related to age and sexual preference. |
|
1.15 Information concerning
criterion performance should be provided. |
User feedback is carefully
qualified when predicting respondents’ compatibility levels. |
|
1.22 When test results imply a
particular outcome, provide users with the basis for prediction. |
This manual is publicly
available on TRUE’s website.
The validation study (Appendix C, online Manual)
is submitted for publication. |
|
1.24 Investigate unintended
consequences. |
Extensive DTF tests
were performed, thus excluding age and sexual orientation as likely causes. |
Table 21: Applicable AERA / APA / NCME Reliability Standards
|
Applicable Standard[14] |
Summary, or reference
to section within this manual |
|
2.1 For each score, subscore,
or combination estimates of reliability and standard errors of estimate
should be given. |
See Section 2, and Section 4,
as well as the SEB Figures 4 through 20. |
|
2.2 Standard error of
measurement should be reported in raw score as well as scale units. |
All measures are in logits as
derived from the Rasch model. |
|
2.4 and 2.11 Consistency of
scores should be expressed for subgroups. |
No noticeable DTF was
found across age and sexual orientation. Hence the SEB
generalize across these groups. |
|
2.5 Reliability coefficients
appropriate to scaling method should be reported. |
Reliability expressed as Rasch
reliability, separation, and SEB, none in terms of
Classical Test Theory. |
|
2.7 When subsets if items
define partially independent traits, reliability estimates should recognize
the multifactor character of the instrument. |
Reliability, separation, and
the SEB are computed separately for each factor. |
|
2.10 When subjective judgment
enters into scoring, the inter-rater as well as within examinee consistency
should be reported. |
All scoring is performed by
software in an online context, no subjective ratings are allowed. |
|
2.11 Publishers should provide
reliability data as soon as feasible for each major population for which the
test is recommended. |
No noticeable DTF was
found across age and sexual orientation. Hence the SEB also
generalize across these groups. |
|
2.14 Conditional standard
errors of measurement should be reported at several score levels. |
Reliability expressed as Rasch
reliability, separation, and SEB. The latter are local and
vary across “scores.” |
Discussion
This report detailed the development of a comprehensive online compatibility test for both heterosexual and same-sex partnering. To our knowledge, the TCT is the only such instrument demonstrated to meet professional standards as outlined by the AERA, APA, and NCME (2002). In addition, the TCT satisfies other pertinent issues:
- The TCT was created and validated as an online test. As stressed by Houran et al. (2004, pp. 521-522), it cannot be assumed that pencil-and-paper tests work equally well (if at all) as the same test administered in an online manner. Indeed, differences in the method of administration (i.e., offline vs. online) may systematically affect respondents’ reactions to the questions. It is mandatory, therefore, that web adaptations of paper-and-pencil instruments be recalibrated based on online administrations. Moreover, the exact same item format and layout should be used during pilot testing and operational use, and online tests should not rely on norms that were established by paper-and-pencil methods (Naglieri et al., 2004).
- On the technical side: The TCT is based on the gold standard of test construction and validation – Item Response Theory (IRT) – and its measurements are not distorted by responses biases related to age, gender, or sexual orientation.
- The scientific rationale and evidence for the TCT is freely available for scrutiny by consumers. As highlighted by Houran et al. (2004), TRUE.com has set an industry standard for consumer education and disclosure by posting its Technical Manual for the TCT (TRUE & Jerabek, 2004). In other words, TRUE.com is the only online matchmaking site that freely and openly substantiates its claims that its testing methods have a firm scientific basis.
These additional features of the TCT directly address the cautions of Finn and Banach (2000) and Houran (2004, Houran et al., 2004) on the lack of standards and regulations concerning online human service practices. We argue that similar standards demonstrated here for the TCT should extend to all online testing services that portray themselves as following the ethical principles of psychological and testing professionals. In this way, consistent standards and regulations for online human service practices will be maintained and consumer confidence in and benefit from such services should increase. This is more than an academic issue. To date, at least one media report (Hahn, 2005) has exposed the trend for matchmaking companies to profit from unsubstantiated personality and compatibility tests. Thompson et al. (2005) recently touched on several of these points as well.
Despite the advancements represented in developing the TCT, two main criticisms can be levied. First, issues of generalizability accompany any non-random sampling procedure in the context of test development and validation. In addition, several authors (Burgess et al., 2001; Mathy et al., 2003) have emphasized the unique methodological issues related to conducting research via the Internet. However, as we have explained here and elsewhere (Houran et al., 2004), Rasch scaling overcomes some of these drawbacks in that its yields essentially population-free parameters. Secondly, it can be argued that the TCT (and other compatibility tests) are incomplete since they do not take into account physical attraction –that indefinable variable of romantic “chemistry.” To be sure, psychologists widely accept that love has at least two primary facets known as Passionate-Erotic Love and Companionate Love. Passionate Love is associated with sexual desire for a partner, whereas Companionate Love represents friendship-type platonic love towards a partner (for a review, see Masuda, 2003). Sternberg (1986) expands this conceptualization in his Triangular Theory of Love and Attachment. According to Sternberg, the amount of love or relationship satisfaction that a person experiences is due to the strength and interaction of three components: Intimacy (the feeling of closeness and bondedness), Passion (the drives that produce romance, physical attraction, and sexual intercourse), and Decision/Commitment (the decision that one loves another and the commitment to continue that relationship).
Clearly then, physical attraction is an important component in the major models of romantic compatibility and relationship development. However, the TCT was designed only to address those variables that appear to help promote and sustain Companionate Love, or what Sternberg might regard as Intimacy and Commitment. The same can also be said of the Wilson Relationship Compatibility Indicator (Wilson & Cousins, 2003b) and various compatibility tests that have not been scientifically substantiated. Most online matchmaking services either adopt physical attractiveness rating systems (e.g., TRUE.com) or simply leave the responsibility of judging the attractiveness of romantic prospects to the test-takers. In short, virtually all compatibility testing methods amount to psychological and behavioral profiling and matching. Still, we would be remiss not to mention a few notable attempts to pseudo-quantify romantic “chemistry.” Wilson and McLaughlin (2001) nicely summarized a wealth of literature on the psychology of perceived beauty and attractiveness. To be sure, there do appear some characteristics – like young age, facial symmetry, and a certain hip-to-waist ratio – that are nearly universally associated with attractiveness.
Of course, common sense and personal experience tell us that physical attraction is also a highly idiosyncratic phenomenon. To this end, the testing firm of weAttract.com has developed a computerized “physical attraction test” that finds photographs of individuals from a pool of online daters that a person will find attractive based on that person’s preferences mapped from a set of prototype faces and body types. Recently, at the 2005 iDate Conference, Fujii Film introduced facial recognition software that parallels the pioneering efforts of weAttract.com. This software reportedly finds matches to photographs a person finds attractive from online dating profiles. Thus, if an online-dater finds Person A and Person B attractive from their photographs, this software will locate other candidates from an online dating pool that resemble the photographs of Person A and B. As noted by Thompson et al. (2005), it remains to be seen whether psychological and physical compatibility can efficiently and validly be synthesized into a single compatibility test and matching system. We anticipate that any successful efforts along these lines would significantly increase the validity of a compatibility test in predicting relationship satisfaction and stability. In the mean time, we appreciate Wilson and Cousin’s (2003a) perspective on the current state of compatibility testing – “It will not tell you whether or not you are going to fall in love with another person in a compulsive, ‘chemical’ way, just whether or not it is a good idea if you do” (p. viii).
Finally, the findings from the TCT development and
validation bear on the issue of which assortative mating model yields greater
relationship quality – “birds of a feather flock together” or “opposites
attract.” We argue that the conflict between the models of similarity and complementarity
is largely illusory. Specifically, we learned from the TCT research that (i)
variables which defined relationship satisfaction formed a hierarchy, and that
(ii) men and women differed quantitatively and qualitatively on those
relationship variables. These findings suggested that men and women in
satisfying long-term relationships agreed on what variables impacted their
relationship quality, but that men and women did not have to agree on the
relative importance of specific variables to achieve that satisfaction. In
other words, relationship satisfaction appears to be grounded partly in
cognitive-behavioral processes, rather than being dependent upon patterns of
gross similarity or dissimilarity. In other words, there were clear gender differences on what makes a
satisfying and stable relationship.
Furthermore, the fact that the TCT measure of romantic compatibility utilizes a planned mixture of similarity and complementarity might partly explain why its scores correlated higher with relationship quality than the correlation Wilson and Cousins (2003b) reported for their similarity-based WCRI measure of compatibility. In addition, future research should re-examine the veracity of existing findings from the perspective of more sophisticated Rasch scaling and Item Response Theory methodologies rather than Classical Test Theory approaches. Our research strongly questions whether widely accepted findings are partly or wholly the result of artifacts related to test biases. To be sure, the cumulative results we have obtained thus far challenge the validity of simplistic models of relationship quality in terms of gross similarity or complementarity. Rasch scaling has elevated “variable-centered” models of assortative mating to a quantitative and qualitative schema or “couple-centered” approach (cf. Luo & Klohnen, 2005). Therefore, broadly speaking, couples with satisfying and stable relationships seem to be distinguished by their ability to integrate qualitatively different issues into the relationship via complex mental processes. Research is underway to understand these complexities in more detail.
Acknowledgments
Development of the TCT was funded by Herb D. Vest. We thank P. Jason Rentfrow, Andy Metcalf, and Kerry McKenna for their assistance in this research and preparation of this report.
References
- Adams, R, & Wu, M. (Eds.) (2002). Pisa 2000 technical report. Paris: The Organisation for Economic Co-operation and Development (OECD) Publications.
- Ahuvia, A. C., & Adelman, M. B. (1992). Formal intermediaries in the marriage market: a typology and review. Journal of Marriage and Family, 54, 452-463.
- American Educational Research Association, American Psychological Association, & National Council on Measurement (2002). Standards for educational and psychological testing. Washington, DC: Author.
- Andrich, D. (1978). Scaling attitude items constructed and scored in the Likert tradition. Educational and Psychological Measurement, 38, 665–680.
- Aries, E. (1996). Men and women in interaction. New York: Oxford University Press.
- Aron, A., Norman, C. C., Aron, E. N., McKenna, C., & Heyman, R. E. (2000). Couples’ shared participation in novel and arousing activities and experienced relationship quality. Journal of Personality & Social Psychology, 78, 273-284.
- Asendorpf, J. B., & Wilpers, S. (1998). Personality effects on social relationships. Journal of Personality and Social Psychology, 74, 1531-1544.
- Bailey, W., Hendrick, C., & Hendrick, S. S. (1987). Relation of sex and gender role to love, sexual attitudes, and self-esteem. Sex Roles, 16, 637-648.
- Baucom, D. H., & Epstein, N. (1990). Cognitive-behavioral marital therapy. New York: Brunner/Mazel.
- Bond, T. G., & Fox, C. M. (2001). Applying the Rasch model: fundamental measurement in the human sciences. Mahwah, NJ: Lawrence Erlbaum.
- Bonebrake, K. (2002). College students’ Internet use, relationship formation, and personality correlates. Cyberpsychology and Behavior, 5, 551-557.
- Bowen, M. (1978). Family therapy in clinical practice. New York: Aronson.
- Bowlby, J. (1969). Attachment and loss: vol. 1. attachment. New York: Basic Books.
- Bowlby, J. (1973). Attachment and loss: vol. 2. separation. New York: Basic Books.
- Bradbury, T. (1998). The developmental course of marital dysfunction. Cambridge, England: Cambridge University Press.
- Bradbury, T. N., Fincham, F. D., & Beach, S. R. H. (2000). Research on the nature and determinants of marital satisfaction: a decade in review. Journal of Marriage and the Family, 62, 964-980.
- Brody, G. H., Ge, X., Kim, S. Y, McBride Murry, V., Simons, R. L., Gibbons, F. X., Gerrard, M., & Conger, R. D. (2003). Neighborhood disadvantage moderates associations of parenting and older sibling problem attitudes and behavior with conduct disorders in African American children. Journal of Consulting & Clinical Psychology, 71, 211-222.
- Brody, L. (1999). Gender, emotion and the family. Cambridge, MA: Harvard University Press.
- Buehler, C., Anthony, C., Krishnakumar, A., & Stone, G. (1997). Interparental conflict and youth problem behaviors: a meta-analysis. Journal of Child & Family Studies, 6, 223-247.
- Burgess, E. O., Donnelly, D., Dillard, J., & Davis, R. (2001). Surfing for sex: studying involuntary celibacy using the Internet. Sexuality and Culture, 5, 5-30.
- Burgess, E. W., & Wallin, P. (1953). Engagement and marriage. New York: Lippincott.
- Cano, A.,& O’Leary, K. D. (2000). Infidelity and separations precipitate major depressive episodes and symptoms of nonspecific depression and anxiety. Journal of Consulting and Clinical Psychology, 68, 774-781.
- Christensen, A., & Heavey, C. L. (1990). Gender and social structure in the demand/withdraw pattern of marital conflict. Journal of Personality and Social Psychology, 59, 73–81.
- Christensen, A., & Shenk, J. L. (1991). Communication, conflict, and psychological distance in nondistressed, clinic, and divorcing couples. Journal of Consulting & Clinical Psychology, 59, 458-463.
- Cohan, C. L., & Bradbury, T. N. (1997). Negative life events, marital interaction, and the longitudinal course of newlywed marriage. Journal of Personality & Social Psychology, 73, 114-128.
- Comrey, A. L. (1978). Common methodological problems in factor analytic studies. Journal of Consulting and Clinical Psychology, 46, 648-659.
- Critelli, J. W., Myers, E. J., & Loos, V. E. (1986). The components of love: romantic attraction and sex role orientation. Journal of Personality, 54, 355-370.
- Crouter, A. C., Perry-Jenkins, M., Huston, T. L., & Crawford, D. W. (1989). The influence of work-induced psychological states on behavior at home. Basic and Applied Social Psychology, 10, 273-292.
- Cummings, E. M., & Davies, P. (1994). Children and marital conflict: the impact of family dispute and resolution. New York: Guilford Press.
- Davies, P. T., & Lindsay, L. L. (2004). Interparental conflict and adolescent adjustment: why does gender moderate early adolescent vulnerability? Journal of Family Psychology, 18, 160-170.
- Downey, G., & Feldman, S. I. (1996). Implications of rejection sensitivity for intimate relationships. Journal of Personality & Social Psychology, 70, 1327-1343.
- Dryer, C. D., & Horowitz, L. M. (1997). When do opposites attract? interpersonal complementarity versus similarity. Journal of Personality and Social Psychology, 72, 592-603.
- Embretson, S. E. (1995). The new rules of measurement. Psychological Assessment, 8, 341-349.
- Embretson, S. E. (1999). Issues in the measurement of cognitive abilities. In S.E. Embretson and S. L. Hershberger (Eds.), The new rules of measurement: what every psychologist and educator should know (pp. 1-16). Mahwah, N.J.: Lawrence Erlbaum.
- Fincham, F. D., Bradbury, T. N., & Scott, C. K. (1990). Cognition in marriage. In F. D. Fincham & T. N. Bradbury (Eds.), The psychology of marriage: Basic issues and applications (pp. 118—149). New York: Guilford Press.
- Finn, J., & Banach, M. (2000). Victimization online: the down side of seeking human services for women on the Internet. Cyberpsychology and Behavior, 3, 243-254.
- Fischer, G. H. (1995). Derivations of the Rasch model. In G. H. Fischer & I.W. Molenaar (Eds.), Rasch models: foundations, recent developments, and applications. (pp. 15-38). New York: Springer.
- Fisher, W. Jr. (1992). Reliability statistics. Rasch Measurement Transactions, 6, 238.
- Fletcher, J. O., Simpson, J. A., Thomas, G., & Giles, L. (1999). Ideals in intimate relationships. Journal of Personality and Social Psychology, 76, 72-89.
- Fowers, B. J., & Olson, D. H. (1986). Predicting marital success with PREPARE: a predictive validity study. Journal of Marital and Family Therapy, 12, 403-413.
- Goeke-Morey, M. C., Cummings, E. M., Harold, G. T., & Shelton, K. H. (2003). Categories and continua of destructive and constructive marital conflict tactics from the perspective of U.S. and Welsh children. Journal of Family Psychology, 17, 327-338.
- Gottman, J. M.,& Krokoff, L. J. (1989). Marital interaction and satisfaction: a longitudinal view. Journal of Consulting and Clinical Psychology, 57, 47-52.
- Gottman, J. M., Coan, C., Carrere, S.,& Swanson, C. (1998). Predicting marital happiness and stability from newlywed interactions. Journal of Marriage and the Family, 60, 5-22.
- Gottman, J. M., & Levenson, R. W. (1988). The social psychophysiology of marriage. In P. Noller & M. A. Fitzpatrick (Eds.), Perspectives on marital interaction (pp. 182–200). Clevedon, England: Multilingual Matters.
- Gottman, J. M., Murray, J. D., Tyson, R., & Swanson, K. R. (2002). The mathematics of marriage: dynamic nonlinear models. Cambridge, MA: MIT Press.
- Gray-Little, B., Baucom, D.H., & Hamby S. L. (1996). Marital power, marital adjustment, and therapy outcome. Journal of Family Psychology, 10, 292-303.
- Graziano, W. G., Jensen-Campbell, L. A., & Hair, E. C. (1996). Perceiving interpersonal conflict and reacting to it: the case for agreeableness. Journal of Personality and Social Psychology, 70, 820-835.
- Grych, J. H., Jouriles, E. N., Swank, P. R., MacDonald, R.,& Norwood, W. D. (2000). Patterns of adjustment among children of battered women. Journal of Consulting and Clinical Psychology, 68, 84-94.
- Guerin, P. J., Fogarty, T. F., Fay, L. F.,& Kautto, J. G. (1996). Working with relationship triangles: the one-two-three of psychotherapy. New York: Guilford Press.
- Guilford, J. P. (1965) Fundamental statistics in psychology and education (4th ed). New York: McGraw-Hill.
- Hahn, J. (2005, Feb 10). Love machines. Los Angeles City Beat. http://www.lacitybeat.com/article.php?id=1650&IssueNum=88. Accessed 2/10/05.
- Hahn, J., & Blass, T. (1997). Dating partner preferences: a function of similarity of love styles. Journal of Social Behavior and Personality, 12, 595-610.
- Hambleton, R. K., Swaminathan, H., & Rogers, H. J. (1991). Fundamentals of item response theory. Newbury Park, CA: Sage.
- Harcourt Assessment, Inc. (2004). Stanford Achievement Test: technical data report. San Antonio, TX: Author.
- Heim, S. C., & Snyder, D. K.(1991). Predicting depression from marital distress and attributional processes. Journal of Marital and Family Therapy, 17, 67-72.
- Hendrick, S. S., Hendrick, C., & Adler, N. L. (1988). Romantic relationships: love, satisfaction, and staying together. Journal of Personality & Social Psychology, 54, 980-988.
- Hoffman, E., & Weiner, M. B. (2003). Love compatibility book: the 12 personality traits that can lead you to your soulmate. Novato, CA: New World Library.
- Holman, T. B. (2001). Premarital prediction of marital quality or break up: research, theory, and practice. New York: Kluwer.
- Houran, J. (2004). Ethics in cross-cultural compatibility testing in Europe: an opportunity for industry growth. Paper presented at the Internet Dating / Online Social Networking Industry Association Inaugural Meeting, Nice, France, July 15-16, 2004.
- Houran, J., Lange, R., Rentfrow, P. J., & Bruckner, K. H. (2004). Do online matchmaking tests work? an assessment of preliminary evidence for a publicized ‘predictive model of marital success.’ North American Journal of Psychology, 6, 507-526.
- Jerabek, I. (1999). Validation study of the Emotional Intelligence Test – R2. Retrieved September 20, 2003 from http://hr.psychtests.com/archprofile/stats/eiq_r2.pdf. Montreal, Canada: Plumeus Inc.
- Jerabek, I. (2000). Psychometric properties and predictive validity of the Relationship Attachment Inventory. Montreal, Canada: Plumeus Inc.
- Jerabek, I. (2003). Validation study of the Relationship Satisfaction Scale. Retrieved September 20, 2003 from http://hr.psychtests.com/archprofile/stats/rel_sat_r.pdf. Montreal, Canada: Plumeus Inc.
- Julien, D., Chartrand, E., Simard, M. C., Bouthillier, D., & Begin, J. (2003). Conflict, social support and relationship quality: an observational study of heterosexual, gay male and lesbian couples' communication. Journal of Family Psychology, 17, 419-428.
- Kelly, E. L., & Conley, J. J. (1987). Personality and compatibility: a prospective analysis of marital stability and marital satisfaction. Journal of Personality and Social Psychology, 52, 27-40.
- Kerr, M. E. (1985). Obstacles to differentiation of self. In A. S. Gurman (Ed.), Casebook of marital therapy (pp. 111-153). New York: Guilford Press.
- Kerr, M. E., & Bowen, M. (1988). Family evaluation: an approach based on Bowen Theory. New York: Norton.
- Kiesler, S., & Kraut, R. (1999). Internet use and ties that bind. American Psychologist, 54, 783-784.
- Kim, I. J., Ge, X., Brody, G. H., Conger, R. D., Gibbons, F. X.,& Simons, R. L. (2003). Parenting behaviors and the occurrence and co-occurrence of depressive symptoms and conduct problems among African American children. Journal of Family Psychology, 17, 571-583.
- Klohnen, E. C.,& Luo, S. (2003). Interpersonal attraction and personality: what is attractive--self similarity, ideal similarity, complementarity or attachment security? Journal of Personality & Social Psychology, 85, 709-722.
- Klohnen, E. C., & Mendelsohn, G. A. (1998). Partner selection for personality characteristics: a couple-centered approach. Personality and Social Psychology Bulletin, 24, 268-278.
- Kurdek, L. A. (1992). Assumptions versus standards: the validity of two relationship cognitions in heterosexual and homosexual couples. Journal of Family Psychology, 6, 164-170.
- Kurdek, L. A. (1993). Predicting marital dissolution: a 5-year prospective longitudinal study of newlywed couples. Journal of Personality and Social Psychology, 64, 221-242.
- Kurdek, L. A. (1996). The deterioration of relationship quality for gay and lesbian cohabiting couples: a five-year prospective longitudinal study. Personal Relationships, 3, 417-442.
- Kurdek, L. A. (1997). The link between facets of neuroticism and dimensions of relationship commitment: evidence from gay, lesbian, and heterosexual couples. Journal of Family Psychology, 11, 503-514.
- Kurdek, L. A., & Schmitt, J.
P. (1986). Relationship quality of partners in heterosexual married,
heterosexual cohabiting, gay, and lesbian relationships. Journal of Personality and Social
Psychology, 51, 711-720.
- Lange, R., Donathan, C.L., & Hughes, L.F. (2002). Assessing olfactory abilities with the University of Pensylvania smell identification test: a Rasch scaling approach. Journal of Alzheimer’s Disease, 4, 77-91.
- Lange, R., Greiff, W. R., Moran, J., and Ferro, L. (2004). A probabilistic Rasch analysis of question answering evaluations. Human Language Technology conference / North American chapter of the Association for Computational Linguistics (NLT / NAACL). Boston, MA, May 2-7.
- Lange, R., Greyson, B., & Houran, J. (2004). A Rasch scaling validation of a “core” near-death experience. British Journal of Psychology, 95, 161-177.
- Lange, R., Houran, J., & Jerabek, I. (2004). Building blocks for satisfaction in long-term romantic relationships: evidence for the complementarity hypothesis for romantic compatibility. Paper presented at the Adult Development Symposium Society for Research in Adult Development Preconference, AERA, San Diego, CA, August 11.[15]
- Lange, R., & Hughes, L. (2004). A computer adaptive Version of the Pennsylvania Smell Identification Test (UPSIT). Advances in Health Outcomes Measurement: Exploring the Current State and the Future Applications of Item Response Theory, Item Banks, and Computer-Adaptive Testing. Bethesda, MD, June 23-25.
- Lange, R., Irwin, H. J., & Houran, J. (2000). Top-down purification of Tobacyk’s Revised Paranormal Belief Scale. Personality and Individual Differences, 29, 131-156.
- Lange, R., Irwin, H. J., & Houran, J. (2001). Objective measurement of paranormal belief: a rebuttal to Vitulli. Psychological Reports, 88, 641-644.
- Lange, R., Jerabek, I., & Houran, J. (submitted). Qualitative and quantitative factors in defining romantic compatibility.
- Lange, R., Thalbourne, M. A., Houran, J., & Storm, L. (2000). The Revised Transliminality Scale: reliability and validity data from a Rasch top-down purification procedure. Consciousness and Cognition, 9, 591-617.
- Lange, R., Thalbourne, M.A., Houran, J., & Lester, D. (2002). Depressive response sets due to gender and culture-based differential item functioning. Personality and Individual Differences, 33, 937-954.
- Larson, R., & Richards, M. (1994). Divergent realities: the emotional lives of mothers, fathers and adolescents. New York: Basic Books.
- Levinger, G. (1986). Compatibility in relationships. Social Science, 71, 173-177.
- Linacre, J. M. (1989). Many-facet Rasch measurement. Chicago, IL: MESA Press.
- Linacre, J. M. (1997). KR-20 or Rasch reliability: which tells the “truth”? Rasch Measurement Transactions, 11, 580-581.
- Linacre, J. M. (2004). WINSTEPS Rasch measurement computer program. Chicago, IL: Winsteps.com.
- Locke, H., & Wallace, K. (1959). Short marital-adjustment and prediction tests: their reliability and validity. Marriage and Family Living, 21, 251-255.
- Luo, S., & Klohnen, E. C. (2005). Assortative mating and marital quality in newlyweds: a couple-centered approach. Journal of Personality and Social Psychology, 88, 304-326.
- Mathy, R. M., Kerr, D. L., & Haydin, B. M. (2003). Methodological rigor and ethical considerations in Internet-mediated research. Psychotherapy: Theory, Research, Practice, Training, 40, 77-85.
- Markman, H. J., Renick, M. J., Floyd, F. J., Stanley, S. M., & Clements, M. (1993). Preventing marital distress through communication and conflict management training: a 4- and 5-year follow-up. Journal of Consulting & Clinical Psychology, 61, 70-77.
- Masters, G. N. (1982). A Rasch model for partial credit scoring. Psychometrika, 47, 149–174.
- Masuda, M. (2003). Meta-analysis of love scales: do various love scales measure the same psychological constructs? Japanese Psychological Research, 45, 25-37.
- McCutcheon, L. E., Lange, R., & Houran, J. (2002). Conceptualization and measurement of celebrity worship. British Journal of Psychology, 93, 67-87.
- Mehrabian, A. (1989). Marital choice and compatibility as a function of trait similarity-dissimilarity. Psychological Reports, 65, 1202.
- Meyer, B., & Pilkonis, Paul A. (2001). Attachment style. Psychotherapy: Theory, Research, Practice, Training, 38, 466-472.
- Michell, J. (1990). An introduction to the logic of psychological measurement. Hillsdale, NJ: Lawrence Erlbaum Associates.
- Mislevy, R. J., & Bock, R. D. (1990), BILOG 3: item analysis and test scoring with binary logistic models, Scientific Sofware Inc., Chicago, IL.
- Mullis, I. V. S., Martin, M. O., Gonzalez, E., Gregory, K. D., Garden, R. A., O’Connor, K. M., Chrostowski, S. J., & Smith, T. A. (2000). TIMSS 1999: international mathematics report. Boston, MA: The International Study Center, Lynch School of Education.
·
Naglieri, J. A.,
Drasgow, F., Schmit, M., Handler, L., Prifitera, A., Margolis, A., &
Velasquez, R. (2004). Psychological testing on the Internet: new problems, old
issues. American Psychologist, 59, 150-162.
- O’Brien, M., & Peyton, V. (2002). Parenting attitudes and marital intimacy: a longitudinal analysis. Journal of Family Psychology, 16, 118-127.
- Panter, A. T., Swygert, K. A., Dahlstrom, G. W., & Tanaka, J. S. (1997). Factor analytic approaches to personality item-level data. Journal of Personality Assessment, 68, 561-589.
- Pasch, L. A., Bradbury, T. N., & Davila, J. (1997). Gender, negative affectivity, and observed social support in marital interaction. Personal Relationships, 4, 361-378.
- Pasch, L. A., & Bradbury, T. N. (1998). Social support, conflict, and the development of marital dysfunction. Journal of Consulting and Clinical Psychology, 66, 219-230.
- Perrone, K. M., & Worthington, E. L. Jr. (2001). Factors influencing ratings of marital quality by individuals within dual-career marriages: A conceptual model. Journal of Counseling Psychology, 48, 3-9.
- Prager, K. (1995). The psychology of intimacy. New York: Guilford Press.
- Queendom.com. (1999). The naked truth about porn. Retrieved September 20, 2003 from http://www.queendom.com/sex-files/pornography/index.html. Montreal, Canada: Queendom.com/ Plumeus Inc.
- Queendom.com. (2000). The joy of passion. Retrieved September 20, 2003 from http://www.queendom.com/sex-files/passion/index.html. Montreal, Canada: Queendom.com/ Plumeus Inc.
- Queendom.com. (2001). Human magnetism. Retrieved September 20, 2003 from http://www.queendom.com/sex-files/attraction/index.html. Montreal, Canada: Queendom.com/ Plumeus Inc.
- Queendom.com. (2002). Sex-a-poll. Retrieved September 20, 2003 from http://www.queendom.com/polls/sexapoll/general/general-q57.html. Montreal, Canada: Queendom.com/ Plumeus Inc.
- Rasch, G. (1960/1980). Probabilistic models for some intelligence and attainment tests. Chicago, IL: MESA Press.
- Robins, R. W., Caspi, A., & Moffit, T. E. (2000). Two personalities, one relationship: both partners’ personality traits shape the quality of their relationship. Journal of Personality and Social Psychology, 79, 251-259.
- Rogge, R. D., & Bradbury, T. N. (1999). Till violence does us part: the differing roles of communication and aggression in predicting adverse marital outcomes. Journal of Consulting & Clinical Psychology, 67, 340-351.
- Ruiz, S. Y., Roosa, M. W., & Gonzales, N. A. (2002). Predictors of self-esteem for Mexican Anmerican and European American youths: a reexamination of the influence of parenting. Journal of Family Psychology, 16, 70-80.
- Schaap, C., Buunk, B.,& Kerkstra, A. (1988). Marital conflict resolution. In P. Noller & M. A. Fitzpatrick (Eds.), Perspectives on marital interaction (pp. 203-244). Clevedon, England: Multilingual Matters.
- Schnarch, D. (1997). Passionate marriage: sex, love, and intimacy in emotionally committed relationships. New York: Norton.
- Schulz, M. S., Cowan, P. A., Pape Cowan, C., & Brennan, R. T. (2004). Coming home upset: gender, marital satisfaction, and the daily spillover of workday experience into couple interactions. Journal of Family Psychology, 18, 250-263.
- Shackelford, T. K., & Buss, D. M. (1997). Spousal esteem. Journal of Family Psychology, 11, 478-488.
- Simpson, J. A. (1990). Influence of attachment styles on romantic relationships. Journal of Personality & Social Psychology, 59, 971-980.
- Skowron, E. A. (2000). The role of differentiation of self in marital adjustment. Journal of Counseling Psychology, 47, 229-237.
- Sternberg, R. J. (1986). A triangular theory of love. Psychological Review, 93, 119-135.
- Stout, W. F. (1987). A nonparametric approach for assessing latent trait dimensionality. Psychometrika, 55, 293-326.
- Stout W. F. (2002). Psychometrics from practice to theory and back. Psychometrika, 67, 485-518.
- Terman, L. M. (1938). Psychological factors in marital happiness. New York: Dryden Press.
- Thompson, M., Zimbardo, P. & Hutchinson, G. (2005). Consumers are having second thoughts about online dating: are the real benefits getting lost in over promises? [Industry Report]. Dallas, TX: weAttract.com. Available online at: http://weattract.com/images/weAttract_whitepaper.pdf.
- Titelman, P. (Ed.) (1998). Clinical applications of Bowen Family Systems Theory. New York: Haworth Press.
·
TRUE, LLC,
& Jerabek, I. (2004). The technical manual for the TRUE Compatibility
Test (TCT). Irving, TX: Author.
- Wainer, H. (2000). Computerized adaptive testing. Mahwah, NJ: Lawrence Erlbaum.
- Waldinger, R. J., Hauser, S. T., Schulz, M. S., Allen, J. P., & Crowell, J. A. (2004). Reading others’ emotions: the role of intuitive judgments in predicting marital satisfaction, quality, and stability. Journal of Family Psychology, 18, 58-71.
- Watson, D., Klohnen, E. C., Casillas, A., Nus Simms, E., Haig, J., & Berry, D. S. (2004). Match makers and deal breakers: analyses of assortative mating in newlywed couples. Journal of Personality, 72, 1029-1068.
- Weissman, M. M. (1987). Advances in psychiatric epidemiology: rates and risks for major depression. American Journal of Public Health, 77, 445-451.
- Whitty, M. T. (2003). Cyber-flirting: playing at love on the Internet. Theory and Psychology, 13, 339-357.
- Whitty, M. T. (2004). Cyber-flirting: an examination of men’s and women’s flirting behaviour both offline and on the Internet. Behaviour Change, 21, 115-126.
- Wieselquist, J., Rusbult, C. E., Foster, C. A., & Agnew, C. R. (1999). Commitment, pro-relationship behavior, and trust in close relationships. Journal of Personality & Social Psychology, 77, 942-966.
- Wilson, G. D., & Cousins, J. M. (2003a). CQ: learn the secret of lasting love. London: Fusion Press.
- Wilson, G. D., & Cousins, J. M. (2003b). Partner similarity and relationship satisfaction: development of a compatibility quotient. Sexual and Relationship Therapy, 18, 161-170.
- Wilson, G. D., & McLaughlin, C. (2001). The science of love. London: Fusion Press.
- Wolak, J., Mitchell, K. J., & Finkelhor, D. (2003). Escaping or connecting? characteristics of youth who form close online relationships. Journal of Adolescence, 26, 105-119.
- Wright, B. D., & Masters, G. N. (1982). Rating scale analysis. Chicago, IL: MESA Press.
- Wright, B. D., & Stone, M. H. (1979). Best test design. Chicago, IL: MESA Press.
Appendix
A:
Additional Factors of the True
Compatibility Test